image-classification的一些常用模型
本文最后更新于:1 年前
CNN
CNN,即卷积神经网络,我们所设计的filter(kernel/neuron),让它去跟图片做卷积,就可以学习我们想要学习的特征.比如我们所设计的filter可以识别出图片的边界情况,则输出的那一个通道的特征图就可以反映图片的边界情况.
但是当我们输入一张猫的图片时,想要学习到猫的特征就需要很多很多个filter.因为一个filter可能学习的是猫的耳朵,一个学的是猫的尾巴,因此需要多个filter,才可以将学习到的局部特征逐渐堆叠称为全局特征.从而完成图像识别的功能.需注意filter的通道数需与输入的特征图的通道数相等.
以上便是卷积层conv所作的事情,即学习图像的特征
而后学习到的图像会有相应尺寸的变化,即原先是一张3*224*224的图片,通过4个3*3*3的filter以1步距的方式卷积后,所得的尺寸变为:4*222*222.很明显图片变小了,此外原图像的边界相较于内部,计算的次数更少,因此可以通过填充空白区域的方式即padding来使得边界像素点和内部像素点获得相同的计算次数.且有padding填充,卷积后的图片大小不变.
而图片中的像素点,并非全部有用.因此卷积后得到的特征图需要经由池化层pooling来减少参数数量,也可以防止模型过拟合,提取图像的更主要的特征.一般来说,我们卷积的操作就是对应元素相乘后求和,因此如果是需要学习的特征,则经卷积层计算后其对应的输出位置的值会比较大.由此,我们的池化层可以对一个小区域内,即利用2*2的filter(步距为2),对区域内的比较大的值进行保留.即为我们的maxPooling.同时也有一种中庸的方法,即对区域内的值取平均,此为averagePooling.
以上便是池化层pooling所做的事情,即提取主要特征并减少参数数量,防止过拟合
最后,我们通过层层的局部特征学习,主要特征提取如此反复的过程,终于得到了一个像样的可以反映输入图片特征的总体特征图,则可以进行分类了.而在分类之前,我们得到的特征图,是一个多维的矩阵,我们期望的输出结果是一个值,因此需要通过全连接层Fully Connected来进行处理.在进入全连接层处理前,我们需要对多维的矩阵进行展平处理,即对应的维度相乘(如1024(C)*7(H)*7(W)),然后通过全连接层(即最基础的神经网络计算方式)将神经元数目变为如100个,然后再经过一个全连接层,将神经元数目变为可分类的种数,如10,再经由softmax处理后,即可取概率值最大的为图像分类的输出值.
需注意,我们的卷积层和全连接层后面都需要跟着激活函数,即对其输出进行非线性化处理.
输入输出尺寸变换计算公式:
其中P是Padding,S是Stride
AlexNet
亮点
- 利用双GPU对网络加速训练
- 采用ReLU激活函数
- 全连接层采用Dropout随机失活神经元,以避免过拟合
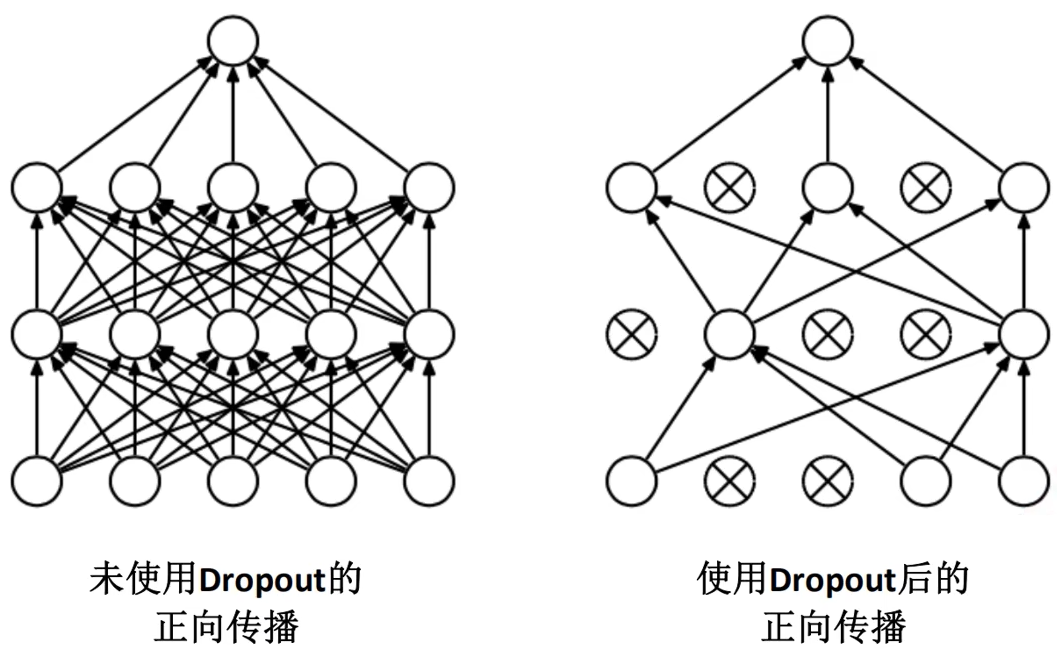
- 采用LRN(后经证实无用)
网络结构图

VGG
亮点
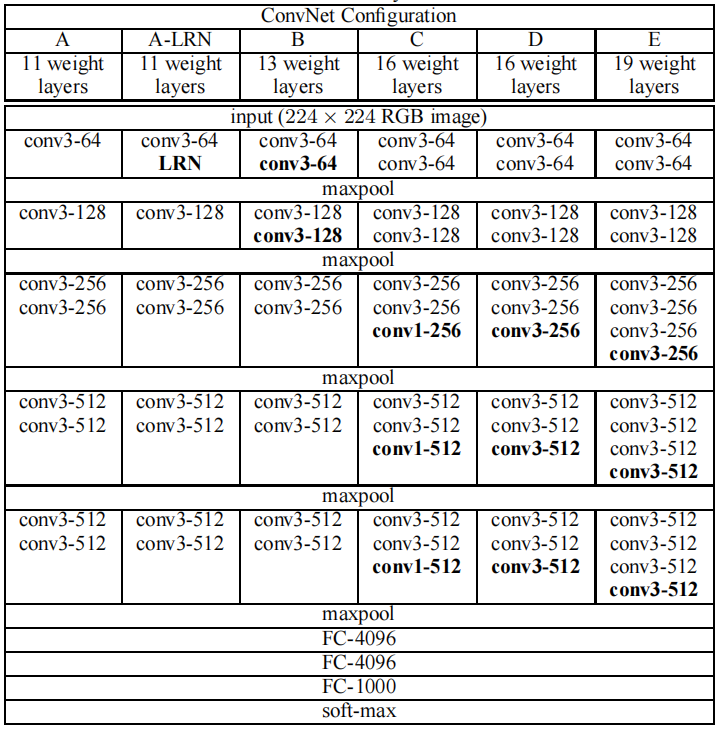
通过堆叠多个3*3的卷积核来代替大尺度的卷积核 ,比如AlexNet里的11*11,7*7这样子的卷积核
如:可以通过堆叠两个3*3的卷积核来替代5*5的卷积核,或者三个3*3的卷积核来替代7*7的卷积核。感受野相同的同时,还减少了计算量。常用的是VGG-16和VGG-19
理论依据:它们拥有相同的感受野
感受野(receptive filed)
在CNN中,某一层输出结果中的一个单元所对应于输入层的区域大小,即为感受野.也就是说在输出的特征矩阵的某一个元素,它对应于输入层上的区域大小
感受野计算公式:
是第层的感受野,Stride是第层的步距,是卷积核或者池化核尺寸
网络结构图
GoogLeNet
亮点
- 引入了inception结构,融合不同尺度的特征信息
- 使用1*1的卷积核进行降维以及映射处理
- 添加两个辅助分类器帮助训练
- 丢弃全连接层,使用平均池化层,减少模型参数
- VGG等只有一个输出层,GoogLeNet有三个输出层(有两个是辅助分类层)
其中最重要的便是前两个创新点,通过借鉴NiN(Network in Network)的思想,利用1*1的卷积核进行降维,此外还增加了网络的非线性(最后用平均池化层替换FC也是出自NiN的思想);而inception结构,所导致的融合多尺度特征信息是指利用横向排列的多个不同尺度的卷积核来获取图像中的信息,即从横向,而非纵向(深度)来进行创新
inception结构块

先看图a,我们的输入层会经过1*1,3*3,5*5这几个不同尺度的卷积核来提取特征以及3*3的最大池化层提取特征。再提取特征通过对padding进行调整使得最终得到的输出的特征矩阵的大小一致,然后在深度上进行堆叠。因此inception结构快可以看作是在水平方向上加深网络;
之所以采取多尺度的卷积核,是因为我们的物体在图片里可大可小,因此若是卷积核选取的不恰当,那么则需要通过加深网络去学习对应的特征,但是随之而来的梯度消失问题也会导致最终的分类效果差强人意。而多尺度的卷积核则规避了卷积核尺寸选取的问题。
而图b是在图a的基础上,增加了1*1的卷积核去降维、聚合以及增加非线性;这可以降低我们的计算量
其实inception结构块可以看作既保持网络的稀疏性(局部连接[相对的是全连接]),又利用了密集矩阵高计算性能
辅助分类器
其实在最后inference的时候,并没有利用到辅助分类器,因为作者认为,中间层产生的特征具有较强的识别力,因此它们对参数修正很重要,所以主要是利用它们的loss来反向更新参数的(除了正常网络的loss外,它们的loss也会乘以一定权重后加到主网络的loss中)。
网络结构图

ResNet
亮点
- 提出了残差结构块
- 利用Batch Normalization加速训练,丢弃了dropout
引言
在介绍接下来的残差结构块和批归一化的操作前。ResNet与先前的VGG或是GoogLeNet的一大差别在与它的layer很多。
而VGG这些先前的网络若是加大layer的话,会面临层数多的反而比层数少的top1error更大,也即分类的结果更加不准确了。
从逻辑上来说,应该不会造成此结果,即我们加多的层若是对原来的特征矩阵只做恒等变换,那么应该不会导致结果更差。
而之所以加多层数出现更糟糕的结果的原因在于:
- 梯度消失/梯度爆炸
- 网络退化问题
梯度消失和梯度爆炸都发生在反向传播的过程中,若系数<1或>1则向前传播误差的时候,则会导致梯度消失或是梯度爆炸的问题,导致结果难以收敛。而层数加深则导致了这个结果。可以通过归一化操作和标准初始化这些操作来处理,本文提出了BN层,用于卷积后对数据的分布进行归一化处理;
而网络退化问题是:当我们适当增加网络层数,训练集loss逐渐下降并趋于饱和,而此时若再增加网络层数,则会出现loss增大的情况(过拟合是loss一直减小)。此时若之前以达到最优,则新加上的层若只是进行恒等映射,那么结果应该依旧是最优的,但是实际结果并非如此,则可以猜测:恒等映射并不容易被神经网络去拟合(实际上并不是恒等映射,而是一些非线性层,是利用非线性层去近似恒等映射,但是很难做到)。而残差结构则解决了这一问题。
残差结构块

在残差结构中,右边的分支则是恒等映射,而主分支则是残差映射,得到的结果是二者相加(而非堆叠)。当我们的网络最优时,残差映射则会为0,它比易于学习!
从信息论的角度来说的话,可以理解为越到深层次的特征图,所含有的信息越来越少了,而通过残差结构则可以使得层的信息比层多
在ResNet中,像ResNet-18和ResNet-34这种较低层次的网络残差结构块如下图左图所示,而像ResNet-50、ResNet-101以及ResNet-152这种深层的网络残差结构块则如下图右图所示:

可见shortcut connection(就是右边的分支,执行的是identity mapping)和主分支它们输出的特征矩阵的shape需要一样才可以相加。而右侧的则考虑了计算量的因素,利用了1*1的卷积核去做降维以及升维的操作。
而在论文中ResNet-34的结构图中,如下示:

可以看到,有一些shortcut的线是实线,即我们上面的残差结构块;而有一些是虚线,则是因为没有池化层,需要对步距进行调整来使得shortcut connection和主分支(也要对步距进行调整)的输出符合论文中给出的网络结构的shape。其残差结构图如下所示:

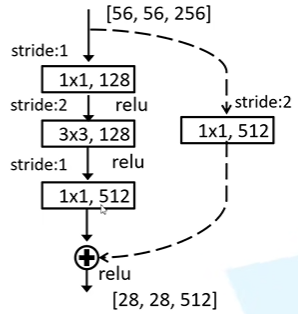
而对于较深层次的网络(如ResNet-50),conv2_x的第一层即conv2_1,可以看见其输入为[56,56,64],而最终的输出为[56,56,256],显然此时就需要在两个分支上都对深度进行变换。
Batch Normalization
Batch Normalization是由Google团队在15年提出的(Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift),通过使用BN层,可以加速网络收敛以及提升准确率。
一般来说我们会在预处理阶段对图片进行标准化处理,目的是加速网络收敛。所谓标准化,就是使得我们的特征矩阵满足某一分布规律,又或者说,就是将一些不太标准的数据通过一定的计算方法将数据统一到指定的格式。
而我们在预处理阶段对图片的标准化处理,只会影响输入层的数据,但是对于中间隐藏层,却没有做到标准化操作。而利用BN层,则可以。
Batch Normalization即批标准化,它的操作对象是batch内的同一layer下同一channel的特征矩阵,对它们进行标准化,使得标准化后的数据满足均值为0,方差为1的分布规律。
大致操作就是:计算出batch内的一layer下的一channel的均值和方差,然后通过对应变换使得生成的满足的分布
显然,batch size应该越大越好,因为希望能代表的是整个训练集的分布规律。而我们在前向传递的过程中统计到的是的值,然后反向传递会得到一个和的值,这两个分别是对统计到的分布规律作scale和shift操作。
此外BN层是放在conv层和激活层间的,而且conv层不要用bias,因为用了结果也一样
后期补充
batch normalization计算公式如下:

一共涉及到四个参数,其中和代表的是训练阶段forward pass时统计得到的两个数值,用于对同一batch内的同维数据做标准化,将同一个batch内的数据分布标准化为正态分布;而和则是训练阶段backward pass时的两个learnable parameter,用于将标准化后的数据做一个仿射变换;
同维
- 对于四维的卷积
[N,C,H,W]指的是同一个channel,而另外的三个维度则拼成一个维度[C,N*H*W],逐channel来计算均值和方差,同样的这时的四个参数的维度都是C维,即有C个,C个,C个,C个 - 对于二维的线性层
[N,n],指的是同一列,即同一个特征,这是四个参数的维度都是n维
个人理解:因为我们是对同一个batch的数据来做normalization(与单纯的standardize不同,还有仿射变换拉回原来的分布特征),那么期望得到的是一个batch内的均值方差,对于图片来说,是规律化的信息,而channel的信息需要单独处理,如果混合处理,会破坏原有的信息
对于训练阶段,会对每个batch都计算各自的均值和方差,并应用该阶段的均值和方差(即batch_mean和batch_var),同时会将该阶段的均值和方差利用滑动平均的技巧与之前那些batch的均值方差进行统计(以得到moving_mean和moving_var),以用作推理阶段;
对于推理阶段,会对每个sample采用训练阶段训练好的滑动均值和滑动方差(moving_mean和moving_var),而另外两个参数则是训练时学到的
具体的计算公式如下:

其中这个滑动平均的思想在训练过程中的做法如下:
1 | |
momentum是动量参数,在Tensorflow中是0.99,在PyTorch中是0.9,初始的moving_mean=0,moving_var=1即为标准正态分布
参考文件:
迁移学习
迁移学习即是使用别人预训练好的模型参数(需要注意别人的预处理方式),能快速训练出较理想结果,且在数据集较小的情况下也能如此。
为何能进行迁移学习呢,就拿卷积来说,我们一开始学习到的是低级特征,比如一些角点信息、纹理信息,其实是通用的,而后学习到的是五官这一类的高级抽象信息,而后再由全连接层对这些信息进行组合输出对应类别的概率。显然前面的低级信息应是通用的。
迁移学习的方式
- 载入权重训练所有参数
- 载入权重后只训练最后几层的参数,如全连接层
- 载入权重后在原net上加多一个fc,只训练最后一个fc
网络结构图

ResNeXt
亮点
利用分组卷积对原来ResNet的主分支变为多个分支进行多路卷积。在参数量相同计算速度相差不大的情况下,提升了准确率,又或者说是融合了Inception结构(split-transform-merge,输入分配到多路,每一路进行变换,最后多路进行结果融合)和ResNet残差结构。
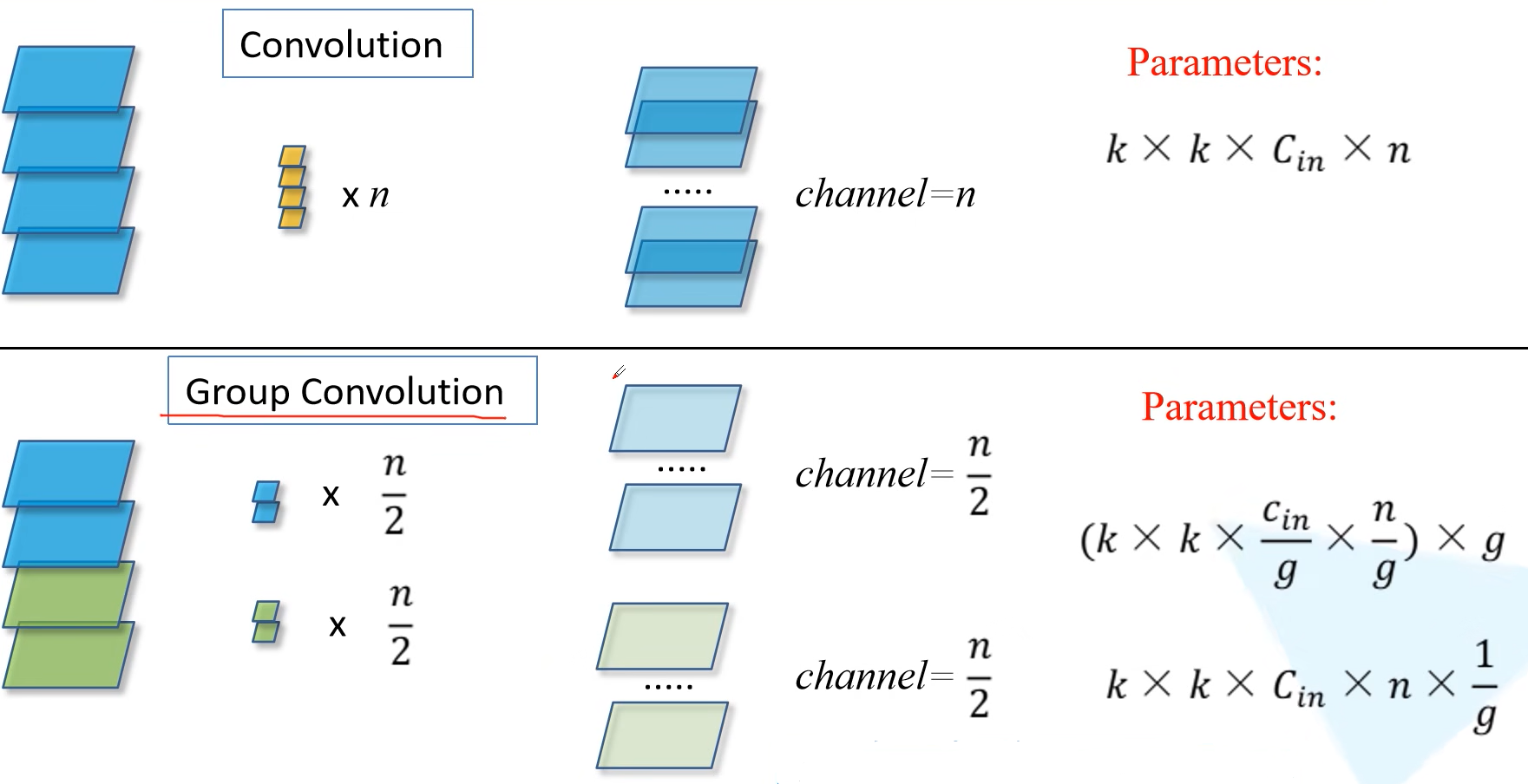
分组卷积
如下图示,对输入图片的维度记作,对输出图片的维度记作,对卷积核的大小记作.对于传统的卷积来说,则每一个卷积核的大小是,然后需要有个卷积核,参数量则是
对于分组卷积而言,我们假设分组的数目是,则每一组卷积核的大小应为,而多组卷积核最后得出的结果需要拼接使得输出的channel为,则意味着我们每一组需要有个卷积核。则其参数量为.可见参数量变为原来的倍。
ResNeXt残差结构
在下图的右边便是ResNeXt的残差结构,可见,它增加了分组的部分,图中的path又或者论文中所提到的cardinality其实指的都是分组的数目。通过Inception结构的split-transform-merge来进行变换。

下图的block模块在数学上是等价的,图C可以看出与原先的ResNet模型的降维卷积升维的操作是一样的,但是在卷积的过程中则利用了分组卷积的思想去减少参数量。

而图B是由图C转换而来的:一个分支对应于一个组,我们的一共有32个分支,也即是有32个分组,因此对输入进行降维的操作,可以将卷积核个数128分配到每一个分支上,即每一个分支的卷积核大小都一样且均为个(注意,此操作不是分组卷积)。而后经由分组卷积操作,然后对结果进行深度方向的拼接再经由升维的1*1的卷积操作,而后便是主分支和shortcut分支相加。
图A则是对图B进行变换而来的:其本质是对卷积核原先内部的相加操作(就是1*1的卷积核原先是对某一坐标下的128个元素分别对应channel相乘而后将各channel的乘值相加,现在依旧是对应channel相乘,但是只有4个channel,而后各对4个channel的乘值相加后变得出特征矩阵,则最后的相加操作,是原先对应坐标下的元素的相加)进行切分
需要注意:ResNeXt的残差结构需要用在ResNet残差结构里有三层以上的才有意义,即需要用在ResNet-50/101/152这些模型身上才有意义。
网络结构图

从以上的网络结构图可以看出ResNeXt-50与ResNet-50结构基本相同,除了多了个分组卷积之外,其中ResNeXt-50右边有个,其中32指代的是分组的数目,4d指代的是每一个组内的卷积核的个数。之所以选择是因在同等计算量下,它的准确度最高。见下图:

MobileNet
前面所提及的模型,它们的权重文件都很大(几百兆),而且对算力也有一定要求,不便于在移动设备上使用。这一部分提及的MobileNet则可以,它是一种轻量级的卷积网络。在准确率小幅下降的情况下,模型参数和运算量大大减少。
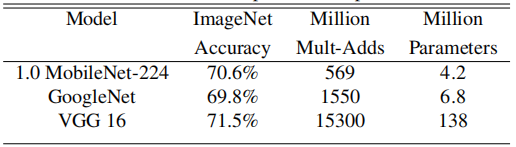
MobileNetV1
亮点
- 深度可分离卷积
- 控制卷积核个数倍率的和控制图像大小的
深度可分离卷积

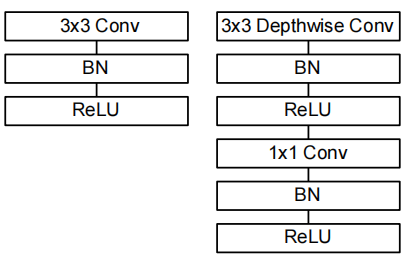
上图便是深度可分离卷积(DSC)和传统卷积的对比图。
深度可分离卷积分为两个过程:逐深度卷积(DW(depthwise)卷积)和逐点卷积(PW(pointwise)卷积) ,其中逐点卷积和普通卷积没啥区别,就是1*1的卷积核卷积。
DW卷积则是逐通道卷积,即卷积核大小为.若输入特征图的深度为则其卷积核的个数亦为,其输出特征图的深度亦为。
PW卷积,则对DW卷积输出的的特征图进行卷积,卷积核大小为,卷积核个数为,最终输出的特征图大小为
DSC相较于传统卷积的好处在于输入输出特征图的大小相同,而计算量和参数量的则大大减少
传统卷积计算量:
DSC计算量:
计算量之比:
传统卷积参数量:
DSC参数量:
参数量之比
而卷积核一般是3*3的,因此能给参数量和计算量降至原来的
在传统的卷积层中,我们常用的是Conv+BN+ReLU这一套作为卷积层。而在DSC中,我们的设置如下图示:
另外,在MobileNetV1中,采用的是ReLU6激活函数,相较于ReLU函数,它有一个上界,其表达式为: 。在低精度浮点数计算时,如8/16位浮点数计算,表达不了那么的大的数,因此用ReLU6在低精度浮点数表示下可以取得比较好的性能。增强鲁棒性。
超参数和
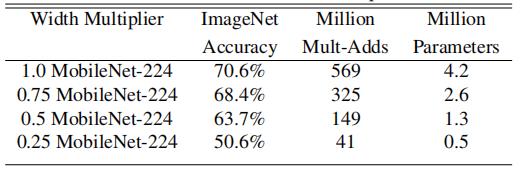
在原论文中称为width multiplier,即宽度乘数,是用它来控制我们每一层的卷积核的个数,它的取值范围是,常用的取值是0.25,0.5,0.75,1。根据个人任务需求来自行在精度和速度(计算量以及内存所占的参数量)取得一个平衡。的各取值效果如下:
在原论文中称为resolution multiplier,即分辨率乘数,隐式的设置,用来控制我们的输入的分辨率。β的取值范围是(0,1],常用的输入分辨率为224,192,160,128。用于在精度和速度(计算量)上取得一个平衡。的各取值效果如下:

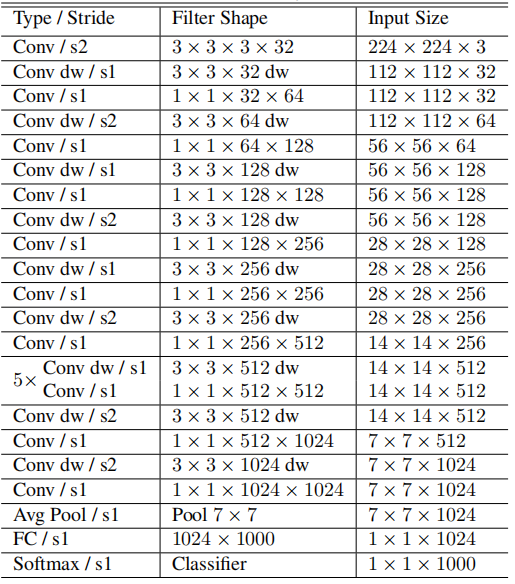
网络结构图
在下图所示的网络结构图中,conv dw即代表DW卷积,在其后面的示PW卷积。可见其即是将通用的卷积层全部替换为DSC。(实际上的网络结构跟VGG差不多)
MobileNetV2
亮点
- 倒残差结构
- 线性的bottleneck
问题提出
在MobileNetV1,存在部分DW卷积核训练出来为0的情况,其产生的原因可以归咎于以下几点:
- DW卷积所用的卷积核个数太少了,因而权重数量太少
- ReLU激活函数,导致一些负数在前向传播置为零,而反向传播其梯度亦为0,使之无法更新
- 低精度,导致小于某一值后,并不能取得值,则归为0
在原文的附录中,其实有对DW为0的情况进行数学分析,可以这么认为,即是ReLU激活函数导致的低维度的信息丢失。下图是,对T的维度进行变换以查看ReLU函数对不同维度信息的丢失程度。可以看出高维的信息经ReLU后丢失较少,而低维信息则丢失较多。

在原先的DSC结构中,我们的DW卷积包含以下过程:DW卷积->BN->ReLU,而一开始的channel的个数其实很少,这即是所谓的低维度,然后经过ReLU处理,很多信息即丢失了,也即意味着:,在这个等式中,我们并不可逆,因而导致了信息丢失。其中x即输入的维度,而则代表对应的权重矩阵,经ReLU操作后,我们的信息会丢失。从数学角度来说,即无法找到唯一解。那么我们现在期望的是尽可能使这个方程能找到唯一解,即意味着可逆(无信息丢失)。
论文中找出了其可逆的条件:中至少个激活为正且中对应的个向量应线性无关
第二个条件易于满足,而第一个条件在论文中,作者说到:当即使之升维,则较大概率保持可逆。因而需要对输入进行升维处理,使之在DW卷积后经ReLU变换,其信息尽量不丢失;对应的在低维度的情况下,我们则不应该采用ReLU变换。并且通过shortcut连接,将DW卷积过程中可能存在的信息丢失予以弥补。
因而提出了inverted residual block(相较于ResNet的先降维后升维而言是inverted)和linear bottleneck(bottleneck是指两个低channel的tensor,这里与ResNet中的bottleneck恰好相反,linear则是代表最后一个低channel的tensor是采用线性激活函数)
倒残差结构
在ResNet中,残差结构是先降维然后进行卷积最后升维以及Add操作,而在MobileNetV2中,则是先升维然后DW卷积而后降维以及Add操作,因而称之为倒残差结构(使得低维信息和非线性变换二者解耦)。
可以对倒残差结构利用压缩文件的思想进行理解:
压缩包(低维度的输入) -> 解压(升维)-> 处理(DW卷积) -> 压缩(降维)
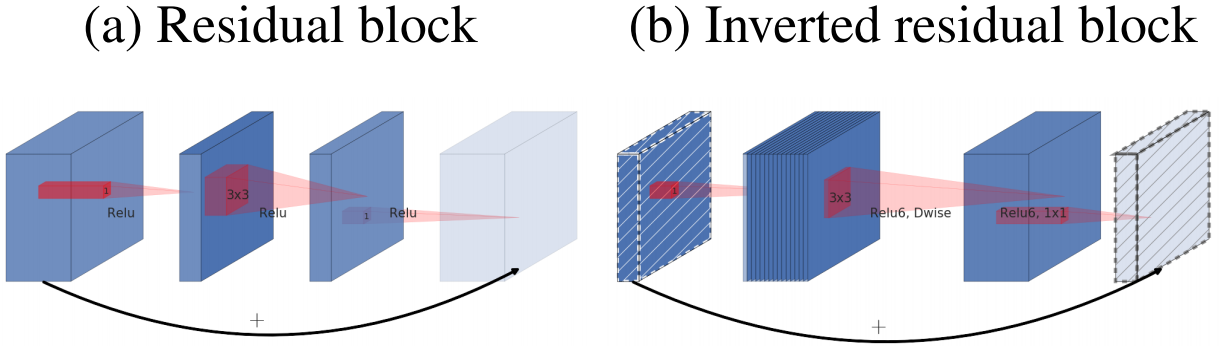
以下是一个倒残差结构的过程图表:

线性的bottleneck
在ResNet中,bottleneck结构是指代残差结构中的卷积过程,而在MobileNetV2中,bottleneck则是指代在DW卷积前后的输入输出两端的低channel的tensor。而线性的bottleneck则是指倒残差结构最后降维处采用了线性激活函数而后输出低维的特征矩阵。
网络结构图
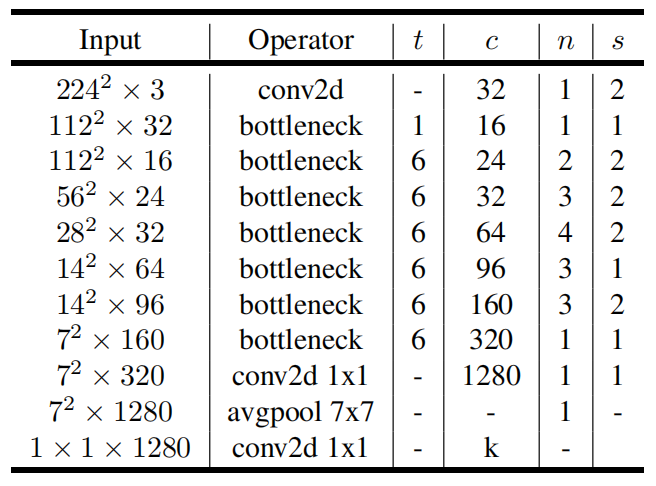
bottleneck则是我们上面的倒残差结构,t则代表了扩展因子,即channel经升维扩充为原来的t倍,c则是降维后的channel个数,n则是指该倒残差结构重复的次数,s则是指dw卷积的步距(该block第一个bottleneck的步距,而后的都是1)。
需要注意,我们可以使得主分支和shortcut分支相加的条件是s=1且两个低维的tensor的shape要相等。
MobileNetV3
亮点
网络结构图
ShuffleNet
EfficientNet
transformer
见blog
ViT
见blog
MobileViT
一些tricks
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!