本文最后更新于:5 个月前
首先构建一个全连接网络,看看它的结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class TestNet (nn.Module ):def __init__ (self, in_dim, hidden_dim1, hidden_dim2, hidden_dim3, out_dim ):super (TestNet, self).__init__()True )True )def forward (self, x ):return xif __name__ == "__main__" :5 , 9 , 9 , 8 , 2 )print (net)
其结构为:
其结构图大致如下(Sequential以layer的标识号区别之,别的亦同)
graph
TestNet-->Sequential1 & Sequential2 & Sequential3 & ReLU
Sequential1 --> Linear1 & ReLU1
Sequential2 --> Linear2 & Sigmoid
Sequential3 --> Linear3 & Tanh
%% layer4 --> ReLU4
而当我们利用net.children()打印时,发现其是generator类型,也即是iterator类型,因此可以通过循环将其输出
1 2 3 4 5 if __name__ == "__main__" :5 , 9 , 9 , 8 , 2 )for i, ele in enumerate (net.children()):print ("{}:{}" .format (i, ele))
其输出结果如下:
可见通过children()获得的结构仅包含最外一层 ,也即可以通过如下方式获得其最外层:print(list(net.children())[0]),即可以获得第0个Sequential:
而通过modules()获得的也是generator类型,因此也用循环将其输出:
1 2 3 4 5 if __name__ == "__main__" :5 , 9 , 9 , 8 , 2 )for i,ele in enumerate (net.modules()):print ("{}:{}" .format (i,ele))
其输出结果为:
可见,其结果类似于深搜,直接把整个结构DFS了一遍
因此可得children()和modules()的区别如下:
通过children()获取网络层级结构,只会取最外层,即根节点下的一层
通过modules()获取网络层级结构,则类似对网络结构进行DFS,依次输出
关于named_children()和named_modules()就不再赘述,因为是在children()和modules()的基础上加了个名字,同样的,它们也是generator类型,可以通过循环遍历,不过对应的是name和module(就是上面代码中的ele),可以通过列表推导式查看相应的结果:
net_named_children = [x for x in net.named_children()]
net_named_modules = [x for x in net.named_modules()]
而net.parameters()和net.named_parameters()打印的是模型每层的参数,而多了个named的方法则是把对应的层/子模块的名称也带上了.可以通过列表推导式来查看相应的结果.通过它们的类型也是generator.
net_parameters = [x for x in net.parameters()]
net_named_parameters =[x for x in net.named_parameters()]
利用模型容器,可以自动的将module注册到网络上 ,以及将module的parameters添加到网络上
将如Conv2d,BatchNorm2d,ReLU等的module放入nn.Sequential容器中,将会按照放置的顺序执行 ,e.g.:
1 2 3 4 5 6 7 8 9 10 11 import torch.nn as nn3 , 256 , 3 , 2 , 1 ),256 ),256 , 512 , 3 , 2 , 1 ),512 ),print (layer1)
其网络层级结构如下所示
其还可以用OrderedDict去为每个module命名,e.g.:
1 2 3 4 5 6 7 8 9 10 11 12 import torch.nn as nnimport collections"conv1" , nn.Conv2d(3 , 256 , 3 , 2 , 1 )),"bn1" , nn.BatchNorm2d(256 )),"relu1" , nn.ReLU()),"conv2" , nn.Conv2d(256 , 512 , 3 , 2 , 1 )),"bn2" , nn.BatchNorm2d(512 )),"relu2" , nn.ReLU())print (layer1)
网络层级结构如下示
该模型容器类似于list,较之nn.Sequential可以更灵活的使用,充当了存放module的容器,执行的顺序在forward中自行定义,较之原生的list,则是可以注册module于网络以及对其参数添加进nn.Parameters()中.e.g.:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import torch.nn as nnclass TestNet (nn.Module ):def __init__ (self ):super (TestNet, self).__init__()3 , 256 , 3 , 1 , 1 )256 )True )256 , 100 ), nn.Linear(100 , 10 )]256 , 200 ), nn.Linear(200 , 10 )]def forward (self, x ):for l in self.layer1:for l in self.layer2:return x
其执行结果表示,用list充当容器,并不能将所需的module注册,而ModuleList则可以,结果如下图示
当我们需要对数据文件进行解析获得数据或者自己创建的数据集ImageFolder不能够满足我们的要求,我们则需要自定义一个Dataset类
而定义好一个Dataset类后,我们可以通过循环或索引得到对应的一条数据,形如data,target,而Sampler则是对这些一条条的数据进行采样的工具,Pytorch提供的主要有SequentialSampler和RandomSampler,这些采样器采样得到的都是这些数据的索引
显然我们一条条读取数据并不能满足我们的需求,我们更期望的是以batch为单位的读取数据,因而有BatchSampler这么一个批采样器,它会对我们Sampler,如SequentialSampler采样得到的一个个索引整理成一个batch_size大小的索引序列
在DataLoader里面,我们便是对BatchSampler这个批采样器采样得到的索引序列进行处理,通过传入的dataset参数读取一条条数据,整理成一个List[Tuple[Tensor,Tensor]]这么一个batch_list的形式,交由collate_fn对这一个batch_size大小的数据进行整理,而后得到我们在循环里对DataLoader遍历的数据
以下展现的是工作进程(num_worker)为0的DataLoader处理方式(跟我上面说的流程一样):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class DataLoader (Generic [T_co]def _get_iterator (self ) -> '_BaseDataLoaderIter':if self.num_workers == 0 :return _SingleProcessDataLoaderIter(self)class _SingleProcessDataLoaderIter (_BaseDataLoaderIter ):def _next_data (self ):if self._pin_memory:return dataclass _MapDatasetFetcher (_BaseDatasetFetcher ):def fetch (self, possibly_batched_index ):if self.auto_collation:for idx in possibly_batched_index]else :return self.collate_fn(data)
自定义一个Dataset类需要的工作:
继承torch.utils.data.Dataset
在__init__中传入需要处理的数据(可能是数据的目录啥的),对数据的预处理方法
在**__getitem__**中完成对数据的解析,预处理,然后返回对应的数据,如return data,target
在__len__中反应需要处理的数据集的大小
自定义一个Sampler类需要的工作:
继承torch.utils.data.Sampler
在__iter__方法中返回一个iterator
在涉及到数据集处理的时候,我们需要考虑到torch.utils.data.Dataset类,以及torch.utils.data.DataLoader类
其中前者是我们对数据集的处理,比如解析数据集数据,然后重写__len__()以及__getitem__()方法 ,而后在其中对数据进行预处理 操作,然后才会得到**data,target这样的数据,其中data可以是图像之类的,而target则可能是标签,GTbox的位置等信息,这时我们通过__getitem__方法 只是获取到一条data,target数据**,处理批量数据的任务则由DataLoader承担
我们在不考虑这一部分将要提及的collate_fn方法前,看一看DataLoader是怎么样将一条数据变成一个batch_size的数据的
以下是代码部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import torchimport torch.utils.data as Data0.4698 , 0.6971 , 0.9499 , 0.3641 ],0.0896 , 0.5345 , 0.5603 , 0.5409 ],0.4988 , 0.2155 , 0.1244 , 0.3456 ],0.4812 , 0.0108 , 0.1885 , 0.8593 ],0.6564 , 0.3428 , 0.8815 , 0.3558 ]])4 , 4 , 1 , 3 , 1 ])for i in dataset:print (f"{i} " )2 for d, t in dataloader:print (f"data:{d} \ntarget:{t} \n" )''' (tensor([0.4698, 0.6971, 0.9499, 0.3641]), tensor(4)) (tensor([0.0896, 0.5345, 0.5603, 0.5409]), tensor(4)) (tensor([0.4988, 0.2155, 0.1244, 0.3456]), tensor(1)) (tensor([0.4812, 0.0108, 0.1885, 0.8593]), tensor(3)) (tensor([0.6564, 0.3428, 0.8815, 0.3558]), tensor(1)) data:tensor([[0.4698, 0.6971, 0.9499, 0.3641], [0.0896, 0.5345, 0.5603, 0.5409]]) target:tensor([4, 4]) data:tensor([[0.4988, 0.2155, 0.1244, 0.3456], [0.4812, 0.0108, 0.1885, 0.8593]]) target:tensor([1, 3]) '''
可见,dataset的结构应是一个Sequential[Tuple[Tensor,Tensor]],而其中一条数据中的tuple里面则包含了data以及target,也即是说通过Dataset我们逐条获取数据得到的是形如(data,target)这样的数据
而显然我们更加希望data归为data,而target归为target,就如用普通的DataLoader得到的结果一样,输出的结果是一个batch的data和一个batch的target
显然DataLoader在其内部即帮我们完成了①按batch_size划分数据;②data为data,target为target
以下,我们采用y = x y=x y = x collate_fn看下输出的结果是什么
1 2 3 4 5 6 loader = Data.DataLoader(batch_size=batch_size, dataset=dataset, collate_fn=lambda x: x)iter (loader)next (it)print (batch_data)
根据输出结果不难看出: 在进入collate_fn之前,数据已经按batch_size划分好了,其结构为:List[Tuple(Tensor,Tensor)],其中List的大小是batch_size的大小,但是数据格式依旧是dataset的结构,因而collate_fn这个方法是用来调整数据格式 的,在我们不调用自定义的collate_fn时,会用系统默认的函数,将输出调整为batch_size大小的data和target这两个部分
以下是等价于系统默认的collate_fn(能将输出划分为data和target两部分):
1 2 3 4 5 6 7 8 lambda x:(0 ) for i in range (len (x))],0 for j in range (len (x[0 ]))
以上是分别对data,target数据进行取出,然后扩充维度,而后对扩充的维度进行拼接,便得到了期望的结果
一般来说,不会用到它,但我在网上以及个人思考后 (pytorch这方面源码没看懂😂),应该是通过torch.stack()进行的维度堆叠,因而如果图片的尺寸或者target中如标签的数目不等,则需要自定义
比如说一个batch_size是2,那两张图片分别是有两个和三个目标,即对应的target为[2,5]/[3,5]无法用stack()对它们简单的拼接,因而需要自己定义一个collate_fn去处理这个问题,自己去定义一个batch出来的数据的格式
以下内容参考文章:
分布式训练
快速上手
计算图可以表示模型中的数据 经过运算 后的流向,是一个有向无环图(DAG),有利于用链式法则计算梯度 。它是由node和edge构成,node表示的是数据,如Tensor等,edge则表示的是计算,如加减乘除、卷积、非线性函数变换等
以上的计算图中,利用代码表示并计算出∂ y ∂ w \frac{\partial y}{\partial w} ∂ w ∂ y
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import torch1. ],requires_grad = True )2. ],requires_grad = True )1 )print (w.grad)
根据链式法则,我们知道,要求
∂ y ∂ w = ∂ y ∂ a ∂ a ∂ w + ∂ y ∂ b ∂ b ∂ w \frac{\partial y}{\partial w} = \frac{\partial y}{\partial a}\frac{\partial a }{\partial w} + \frac{\partial y}{\partial b}\frac{\partial b}{\partial w}
∂ w ∂ y = ∂ a ∂ y ∂ w ∂ a + ∂ b ∂ y ∂ w ∂ b
即是对y到w上涉及到的路径进行求和,而路径则是依次求偏导相乘得到的。从图及上式可知∂ y ∂ w = a + b \frac{\partial y}{\partial w} = a+b ∂ w ∂ y = a + b
此外,我们知道原函数,即a = w + x a = w+x a = w + x y = a ∗ b y = a*b y = a ∗ b Tensor中提供了grad_fn属性,便于获取不同运算方式时的求导规则。
以下是在上面代码补了几行print,打印出grad_fn
1 2 3 4 5 6 7 print (a.grad_fn)print (b.grad_fn)print (y.grad_fn)
上图给出的例子中,x和w均是输入值,是作为图中的叶子节点存在的,如果没有特别标明,在反向传播求完梯度后,非叶子节点的梯度是会被释放的,只保留叶子节点的梯度,如需保留非叶子节点的梯度,可以利用retain_grad属性标明
以下是演示代码及结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import torch1. ],requires_grad = True )2. ],requires_grad = True )1 )print (w.grad)print (a.grad_fn)print (b.grad_fn)print (y.grad_fn)print (a.is_leaf,b.is_leaf,y.is_leaf)print (x.is_leaf,w.is_leaf)print (a.grad,b.grad,y.grad)''' tensor([5.]) <AddBackward0 object at 0x00000266EE747208> <AddBackward0 object at 0x00000266EE747208> <MulBackward0 object at 0x00000266EE747208> False False False True True tensor([2.]) tensor([3.]) None '''
详细区别可见:cs231n-lecture08-pdf
PyTorch中的计算图是动态生成的,即类似于解释型语言,它是在运行过程中动态生成的;
Tensorflow的计算图则是静态生成的,即类似于编译型语言,是先生成计算图,而后进行运算。
显然动态生成的更灵活,利于定位错误,进行debug;静态生成的则可以进行优化,更高效些。
PyTorch和Tensorflow现也各自都有动态和静态的计算图于各自的子库中
当我们从torchvision.models中去导入一个模型的时候,比如resnet18
from torchvision.models import resnet18
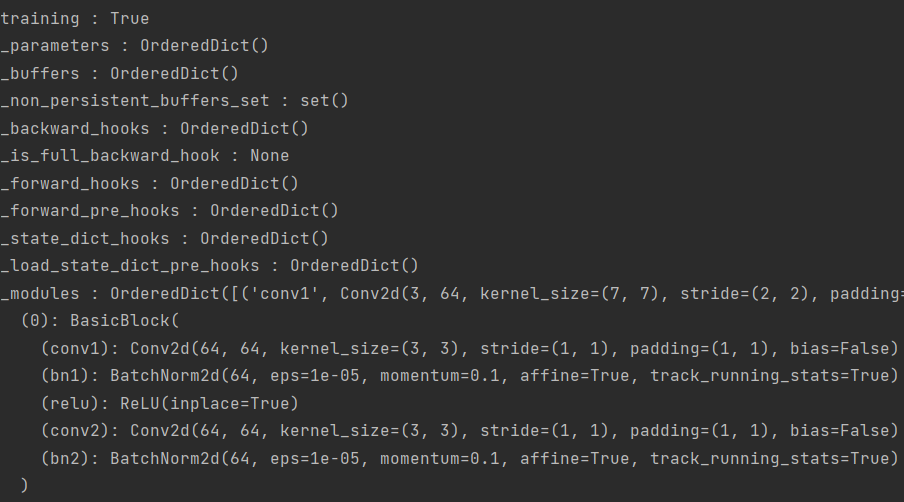
我们通过print(model) # resnet18会打印出模型详细的层信息,这些个层信息是经由OrderedDict包装过的,即是通过该结构对层信息进行重命名
我们可以通过model.__dict__来查看模型的内部信息,为了便于查看,我们遍历着看:
1 2 3 4 5 6 7 8 9 import torchimport torch.nn as nnfrom torchvision.models import resnet18"cuda" if torch.cuda.is_available() else "cpu" )print (model)for k, v in model.__dict__.items():print (k, ':' , v)
以下是模型内部信息打印结果(没截全):
不难看出,模型内部信息包含了丰富的内容,其中我们这里关注_modules属性,通过它我们可以很方便地对模型的层信息(子模块)逐层遍历
我们通过model.__dict__[_modules]获取模型的层信息,其中获取到的层信息是用OrderedDict包装过的,因此进行如下遍历:
1 2 3 4 5 6 7 m_dict = model.__dict__['_modules' ]for name, sub_module in m_dict.items():print ("sub_module_class:" , sub_module_class)print ("sub_module_name:" , sub_module_name)print ("name:%s\n" % name)
以下是部分遍历结果:
通过递归可以对子模块进行完整的遍历,因为有些子模块是通过模型容器封装的,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import torchimport torch.nn as nnfrom torchvision.models import resnet18def recursively_iter_sub_module (module_dict, module_forward_dict ):for name, sub_module in module_dict.items():if sub_module is None or isinstance (sub_module, torch.nn.Module) is False :break print ("sub_module_class:%s\nsub_module_name:%s\nname:%s" %'_modules' ]if len (sub_sub_modules) == 0 :elif len (sub_sub_modules) > 0 :if __name__ == "__main__" :"cuda" if torch.cuda.is_available() else "cpu" )'_modules' ]for module, forward in sub_module_forward_dict.items():print (module, ":" , forward)
这里通过{module:forward}把所有的子模块按顺序封装了是为了后续便于对forward重封装
以下是部分运行结果图:
pytorch的hook有针对Tensor的,也有针对module的,涉及到的函数如下:
graph LR
hook --> Tensor & Module
Tensor --> register_hook
Module --> register_forward_hook & register_forward_pre_hook & register_full_backward_hook & register_full_backward_pre_hook
register_hook(hook)当对应tensor的梯度计算完的时候,这个钩子函数(即里面的hook)会被调用,该钩子函数可以用来打印中间节点的梯度信息,甚至修改计算完的梯度(虽然pytorch不建议你这么做) ,这个register_hook()返回值是一个handle(RemovableHandle类的),这个handle可以调用remove()方法移除对应tensor的钩子函数
钩子函数的声明需要遵循如下规则:
1 hook(grad) -> Tensor or None
输入是这个tensor对应的梯度,返回值是一个Tensor或一个None值
用例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import torchif __name__ == "__main__" :2. , requires_grad=True )3. , requires_grad=True )print (c)lambda grad: print ("cc:" , grad)4. , requires_grad=True )lambda grad: grad * 2 )print (a.grad, b.grad, d.grad)6. , grad_fn=<MulBackward0>)4. )12. ) tensor(8. ) tensor(12. )
上述a,b,d均为计算图中的叶子节点,c,e为中间节点,因此当我们完成反向传递后,计算图会释放中间节点的梯度,我们可以通过上面说的retain_grad()的方式去保留某些tensor的梯度,也可以像上述通过钩子函数,在该张量算完梯度后,把其梯度值钩出来(因为没有retain,反向传播完后还是会释放)
此外,上述也通过lambda表达式对d的梯度值进行了修改,变成了原来的2倍,原本应该是6的,现在d的梯度是12
用于Module的钩子函数在注册的时候返回值也是一个handle,也可以通过handle.remove()移除对应Module的钩子函数,以下对它们各自的钩子函数的声明进行介绍,并且展示一个统一的用例
其中,钩子函数可以用于Module(nn.Module)的子类,如一些基础的算子Conv2d,BatchNorm2d,可以提取它们activation等,也可以将中间层的结果可视化处理
register_forward_hook(hook)注册的钩子函数是在forward完成后被调用,钩子函数的声明如下:
1 hook(module, args, output) -> None or modified output
register_forward_pre_hook(hook)注册的钩子函数是在forward执行前被调用,钩子函数的声明如下:
1 hook(module, args) -> None or modified input
register_full_backward_hook(hook)注册的钩子函数在backward完成后被调用,钩子函数的声明如下:
1 hook(module, grad_input, grad_output) -> tuple (Tensor) or None
register_full_backward_pre_hook(hook)注册的钩子函数在backward执行前被调用,钩子函数的声明如下:
1 hook(module, grad_output) -> tuple [Tensor] or None
总用例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 import torchimport torch.nn as nnimport torch.optim as optimclass TestNet (nn.Module ):def __init__ (self ):super (TestNet, self).__init__()1 , out_channels=2 , kernel_size=3 , stride=1 )2 , stride=2 )def _initial_weights (self ):0 ].data.fill_(1 )1 ].data.fill_(2 )def forward (self, x ):1 )return xdef forward_hook (module_name=None ):def _forward_hook (module, input , output ):print ("---" * 15 , "forward pass" , "---" * 15 )print ("Module Name: {}" .format (module_name))print ("Input Shape: {}" .format (input [0 ].shape)) print ("Input: {}" .format (input ))print ("Output Shape: {}" .format (output.shape))print ("Output: {}" .format (output))print ("-" * 104 )return _forward_hookdef backward_hook (module_name ):def _backward_hook (module, grad_input, grad_output ):print ("---" * 15 , "backward pass" , "---" * 15 )print ("Module Name: {}" .format (module_name))if grad_input[0 ] is not None :print ("Gradient Input Shape: {}" .format (grad_input[0 ].shape))print ("Gradient Input: {}" .format (grad_input))print ("Gradient Output Shape: {}" .format (grad_output[0 ].shape))print ("Gradient Output: {}" .format (grad_output))print ('-' * 105 )return _backward_hookif __name__ == "__main__" :.0001 )for name, module in model.named_modules():if isinstance (module, nn.Module) is False : continue if len (module._modules) == 0 : 1 , 1 , 4 , 4 ])0 , 10 , [1 , 2 ], dtype=torch.float )print ("fake label shape: {}\nfake label:{}" .format (fake_label.shape, fake_label))print ("y_logit shape:{}\ny_logit{}" .format (y_logit.shape, y_logit))
运行结果如下图:
具体使用可以参考:pytorch-hook使用指南
通过以下指令查看物理CPU数目 :
cat /proc/cpuinfo | grep 'physical id'| sort | uniq | wc -l
通过以下指令查看每个CPU的核心数 :
cat /proc/cpuinfo | grep 'core id' | sort | uniq | wc -l
以上,我们就可以计算出CPU的总核心数
总核心数=物理CPU数目*每个CPU的核心数
而一般来说,一个核心就对应一个物理线程,而有个叫超线程 的技术,可以把一个核心当作两个线程来用,也就相当于像两个核心一样.而总逻辑CPU数就是在总核心数的基础上乘上超线程的倍数
总逻辑CPU数目=物理CPU数目*每个CPU的核心数*超线程系数
可以通过以下指令查看总逻辑CPU数目
cat /proc/cpuinfo | grep 'processor' |sort | uniq | wc -l
关于逻辑CPU的体现,比如top指令中的%CPU表示的是占用的逻辑CPU数目
这个线程数默认是CPU核心总数 ,可以通过torch.get_num_threads()获得,且一般默认的运算效率是最高的
需要设置这个的场景是当多人共享CPU资源进行模型运算 时用的,以避免一个进程抢占过多的CPU核心
除了通过torch.set_num_threads()设置,还可以通过环境变量设置,如:MKL_NUM_THREADS和OMP_NUM_THREADS来设置,它们的优先级如下:torch.set_num_threads() > MKL_NUM_THREADS > OMP_NUM_THREADS
其中一般要运用到这个设置是利用CPU进行大量张量操作 ,若是大部分的张量操作都是在GPU上,那设置这个也没啥用,且设置的时候由于PyTorch文档没有说哪些运算会从这个设置上受益,因此建议一边看着CPU利用率一边调整线程数,以最大化CPU利用率
这些设置的线程应该是用于算子内并行 (intra-op parallelism)的
DataLoader中的num_worker是用于指定加载数据和执行变换的并行worker的数目.如果你在加载很大的图片或者有着复杂的变换操作时,即是此时你的GPU处理数据很快,但是你的DataLoader喂数据给GPU很慢而导致不能连续feed GPU,这种情况下就可以设置较多的worker来解决问题
一般对num_worker的设置是直到epoch中的一个step是足够快的(也就是数据可以及时喂给GPU)
注意:num_worker用到的也是计算机的CPU核心数
本部分内容大多学习自:ddp中的核心数和线程数 、pytorch模型在multiprocessing下前馈速度明显降低的原因是什么?
疑惑点:如果我是CPU+GPU计算,那么设置num_worker加速数据读取就好,那如果我是纯CPU计算,我默认我set_num_threads用的是CPU所有核心数,那我num_worker会抢占资源嘛,还是用的是超线程的(如果有)
torch的内存连续性体现在数据排布在内存上是行主序:
1 2 3 4 a = torch.randn(3 ,5 )print (a.shape) print (a.stride()) print (a.is_contiguous())
对它的形状进行一些变换操作,如转置:
1 2 3 4 a_t = a.transpose(0 ,1 )print (a_t.is_contiguous()) print (a_t.shape) print (a_t.stride())
即意味着只变更了shape和stride而没有真正意义上对数据进行挪动,以使之满足内存连续性,需要进行a_t.contiguous()才可以使之重新排布数据以满足行主序
个人感觉类似于cute对其定义的Tensor的操作,即对张量的形状变动并不真正触及内存排布的更改,只是修改了访问方式
之于torch,需要在一些依赖张量内存布局的操作(如view()操作)前通过tensor.contiguous()使得张量变为内存连续的以执行相应操作,同时张量内存连续的话有利于torch潜在的性能优化(联想到大字长访存等等)
参考文件: