tqdm是一个可视化的进度条,用法如下:
1 2 3 4 5 6 from tqdm import tqdmimport timerange (100 )for i,e in enumerate (t_bar):0.2 )
上述便是tqdm的一个例子,无需print便会在控制台自动输出对应内容的进度条信息
以下是tqdm这个类可接收的参数信息
1 2 3 4 5 6 7 def __init__ (self, iterable=None , desc=None , total=None , leave=True , file=None , ncols=None , mininterval=0.1 , maxinterval=10.0 , miniters=None , ascii =None , disable=False , unit='it' , unit_scale=False , dynamic_ncols=False , smoothing=0.3 , bar_format=None , initial=0 , position=None , postfix=None , unit_divisor=1000 , write_bytes=None , lock_args=None , nrows=None , colour=None , delay=0 , gui=False , **kwargs ):
iterable: 接收可迭代对象
desc: 接收str,用于进度条左侧显示文字
total: iterable的迭代总次数
leave: 接收bool值,迭代完成后是否保留进度条,默认True
file: 输出位置,默认终端
ncols: 进度条宽度
unit: 进度条里的单位,默认是it,显示于2.28 it/s,即更改的是it这个单位
unit_scale:默认False,开启则代表根据国际标准对速度单位进行换算
postfix: 接收dict,传入信息显示于进度条右侧
colour: 进度条颜色
此外,除了在构建进度条时设置的内容,在进度条内部的迭代对象在迭代过程中的元素也可以加入进度条中进行显示,通过如下方式增加:
set_description(): 显示于进度条左侧set_postfix(): 显示于进度条右侧
例子如下:
1 2 3 4 5 6 7 8 9 10 import randomfrom tqdm import tqdmimport timerange (200 )"train" , colour="green" )for i, e in enumerate (tbar):0.4 )"epoch[{}/{}]" .format (i, 200 ))100 ))
注意:set_postfix传入的参数是**kwargs,即可传入dict(** -> 表示接收可变长参数,以字典形式接收之,同样单星号也是接收可变长参数,不过是以list形式接收之),也可以关键字形式传入
用于编写命令行接口.对我们指定的参数可以通过命令行的长指令写入并在程序中解析.例子如下
1 2 3 4 5 6 7 8 9 10 11 import argparse"demo of argparse" )"--epoches" , type =int , default=5 , help ="epoch of the model" )"--lr" , type =float , default=.0001 , help ="learning rate of the gradient" )print ("epoches: {} lr: {}" .format (args.epoches, args.lr))
在终端中输入python ./xxx.py --epoches=100 --lr=0.005即可以将对应的参数输入并于程序中解析.同时也可以查看对应的帮助文档python ./xxx.py -h
我们知道tensorboard是用于模型训练验证中的可视化,比如记录loss,accurate变化(以曲线图形式表征之)
而SummaryWriter这一个类则可以向tensorboard中写入对应的数据信息
SummaryWriter是tensorboard下属的一个类,它会write out event file在我们的项目下,默认存储事件文件的文件夹是runs,可通过如下方式修改:
1 event_writer = SummaryWriter("logs" )
因此当我们run当前的python文件就会在当前项目下产生一个logs文件夹,并且里面存放着刚刚运行后的event file.
有了event file后便可以查看可视化后的内容,在终端输入:
1 tensorboard --logdir=logs
之后便可以打开终端显示的链接localhost:6006来查看可视化后的内容(端口号可以通过--port=xxx来修改)
显然,此时你看不到有啥可视化后的内容,因为你还没将需要可视化的数据写入tensorboard中
1 2 3 4 5 6 7 8 9 10 11 from torch.utils.tensorboard import SummaryWritter"logs" )''' tag -> 在tensorboard上显示的名字,类似于该图对应的标题 scalar_value -> 相当于纵坐标对应的值 step -> 相当于横坐标对应的值 ''' "train_loss" ,train_loss,epoch)
1 2 3 4 5 6 7 8 9 10 11 12 event_writer.add_image(tag,img_tensor,step,dataformats)''' tag -> 在tensorboard上显示的名字,类似于该图对应的标题 img_tensor -> img的数据,允许numpy.ndarray;torch.Tensor;string等 step -> 好像也是横坐标对应的值 dataformats -> img的shape对应的是HWC还是CHW ''' "./tulip.jpeg" open (img_path)"tulip" , img_ndarray, 1 , dataformats='HWC' )
最后,使用完后记得关闭之event_writer.close()
fvcore是Facebook开源的轻量核心库,可以用于计算浮点运算量(FLOPs,计算量),模型参数量 等
注:
FLOPS是floating point operations per second,每秒浮点运算次数,即计算速度;
FLOPs是floating point operations,浮点运算量,即计算量
简单使用如下所示:
1 2 3 4 5 6 7 8 9 import torchfrom torchvision.models import resnet50from fvcore.nn import FlopCountAnalysis,parameter_count_table1000 )1 ,3 ,224 ,224 )print (parameter_count_table(model))print ("FLOPs: {}" .format (FLOPs.total()))
用于计算笛卡尔积,e.g.:
1 2 3 4 5 import itertools1 , 2 ], [3 , 4 , 5 ])for i, ele in enumerate (output):print ("{}:{}" .format (i, ele))
输出结果:
它的property有repeat,即是将前面的元素笛卡尔积的结果,作为新元素,重复repeat遍,然后做笛卡尔积,e.g.:
1 2 3 4 5 6 7 import itertools1 , 2 ], [3 , 4 , 5 ], repeat=2 )for i, ele in enumerate (output):print ("{}:{}" .format (i, ele), end="\t" )if (i + 1 ) % 4 == 0 :print ("" )
输出结果:
在方法中标注@property这样的注解,可用于将变量私有化(毕竟python提供的伪私有类型是伪的),此时方法便可以像成员变量一样使用.e.g.:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Test (object def __init__ (self, _scale ): @property def scale (self ):return self._scale5.0 )print (t.scale)print (t.scale())
由此可见,加上@property就是把一个function变成了variable,用以保护其内部真正的成员变量名
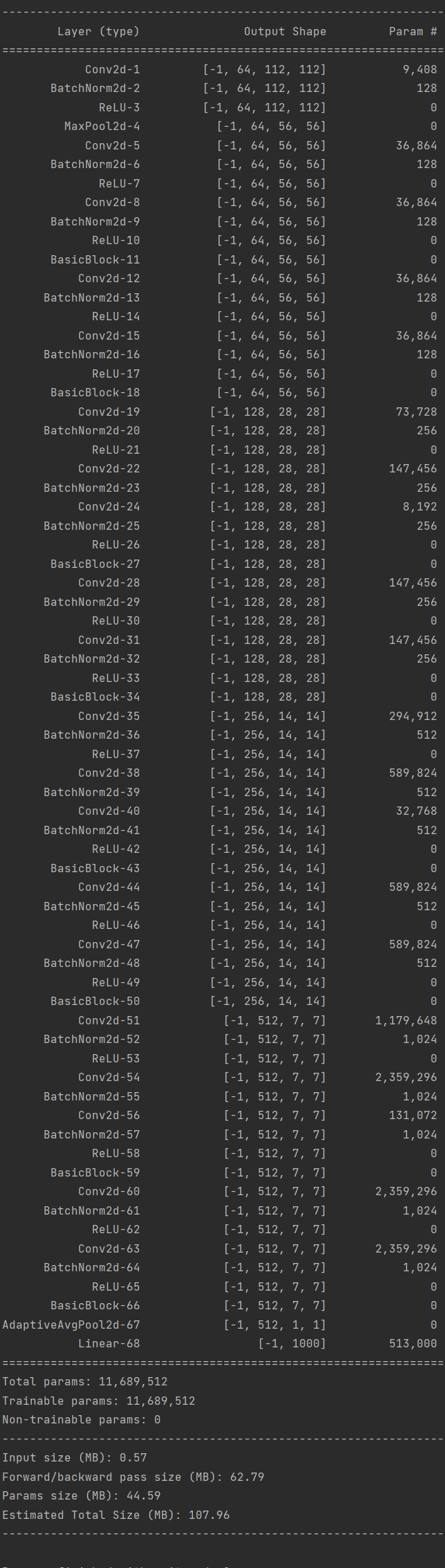
torchsummary和torchstat、profile这些库一样,可以计算出模型中每层的参数量,总参数量,参数大小等信息,后面的两个库可以计算出flops等信息,这些库需要提前安装一下。
以下是torchsummary的使用案例:
1 2 3 4 5 6 7 8 import torchfrom torchsummary import summaryfrom torchvision.models import resnet50"cuda" if torch.cuda.is_available() else "cpu" )3 , 224 , 224 ))
输出结果为
copy这个库,可以当我们在需要的时候对对象做深浅拷贝
以下是示例,结合示例进行分析,其中copy.copy()是浅拷贝,copy.deepcopy()是深拷贝
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import copy'def' 1 , 'a' , ['b' , 'c' ], one]1 ] = l1[-1 ] + 'g' 2 ].append('d' )'test' )print ("one:" , one)print ("l1:" , l1)print ("l2:" , l2)print ("l3:" , l3)print ("l4:" , l4)
运行结果如下:
不难看出在l1中我们增加了作为str对象的one,但是l1并没有跟one一起指向同一块地址(那就是new了一块新的空间给它),因此在后续对该列表值修改的时候,并没有影响到one对象的值;
对于直接赋值的l2应该跟l1指的是同一块地址;
对于浅拷贝的l3,只是拷贝了深拷贝的第一层(父对象),对于里面的父对象内部的对象,则是指的同一块地址;
对于深拷贝的l4,则对全部对象内容进行了拷贝