CUDA学习积累(持续更新)
本文最后更新于:2 个月前
前情提要
在去重庆参会前,就已经自己构建了一套学习理论(算子编写,算子调度[分布式模型训练])听了山城会议之后,觉得对于算子编写得尽快提上日程,因此打算结合视频和博客学习CUDA,每天花点时间学习整理,方便后续算子编写的工作。
目前第一部分的学习首先是结合B站的视频展开:CUDA 编程入门,后续学习到的知识重复部分则不予更新,更新尚未了解的部分~
CUDA学习
什么是GPU计算
介绍了CPU的一般架构,可能涉及到多个核心,然后有L1、L2、L3多级cache缓存。主要意思是说:CPU核心数目不会特别多,一般多的话也就几十个
介绍GPU一般架构,有SM(Streaming MultiProcessor),一个SM里面有多个SP(Streaming Processor),它内存有L1、L2多级cache,也有全局系统显存
一个SM里面会包含许多SP(也叫CUDA Core),同时也有指令Cache,warp调度器,寄存器文件等
GPU和CPU一起做运算,GPU(device)负责计算密集型任务,CPU(host)负责控制密集型任务,它们通过PCIe相连接(拷贝数据到对方的存储空间,好像也有共享内存类型的)
CPU所谓的线程其实是伪进程(云计算课老师说的),上下文切换开销大
GPU的线程则是真正意义上的线程,是很轻量级的
CUDA支持C/C++编程,也支撑Fortran,Python
- 编译器:nvcc(nvidia cuda compiler)
- 调试器:nvcc-gdb
- 性能分析:nsight,nvprof NsightCompute
- 函数库:cuBLAS,cuSparse,…
- 二进制工具: cuobjdump,nvdisasm cuda-binary-utilities
GPU内存层次

上图呈现的是GPU的逻辑内存层次结构,分为grid-block-thread,其中我们在CUDA中会通过**dim3**类型来对它们进行定义,dim3类型可以理解为结构体,内部有x,y,z三个值(空间直角坐标系),默认缺省值为1
grid(网格)内部有多个block(线程块),block内部有多个thread(线程),在编写CUDA程序时,会分为host端和device端(异构编程模型嘛),我们在调用核函数的时候,会通过执行配置参数,声明这一个核函数需要用到的grid和block
而在核函数内部,会有如gridDim,blockDim这两个内置参数来查看外部声明的配置参数的大小,并且可以通过blockIdx,threadIdx找到对应block属于grid的第几行第几列,对应thread在block内的线程号以及相对于整个grid它的线程号等信息
实际上GPU的内存层次并非上述的grid-block-thread,这一概念是为了将软硬件剥离,以提高程序员编写的简易性,但若是考虑到性能优化,就一定需要了解其真正的物理内存层次,下图展示的是Fermi架构的内存层次,gpu硬件的内存层次整体大同小异

可以看到上述分为了两个层次,第一个层次是许多的SM由DRAM(全局内存,就是通俗意义的显存)围绕,而内部所有的SM共享一个L2Cache,也就是SM们可以通过L2Cache进行通信;
右侧展开了单个SM,可以看到内部有许多的CUDA Core(SP),还有L1Cache和Shared Memory所共享的64KB内存,以及一个超大的Regster File,其中内部还包括warp的调度器,发射单元等部件
实际上,我们的block它在运行的时候会被调度到SM上(SM是真正的核心组件),一个SM可以调度多个block,具体多少,看它的资源,因为我们线程的寄存器,线程块的共享内存,是用的SM的资源.而在SM上的一个block会被划分为多个warp,一个warp是32个线程,warp是最基本的执行单元,warp内部遵循SIMT,每个线程同时执行相同的指令,而每个线程它拥有自己独立的PC和寄存器状态,也即有自己的执行路径
因此block应该设置为32的倍数,如果不是32的倍数,余下的部分会单独划为1个warp,该warp除了需要的线程,剩余的线程都是inactive
下面是关于逻辑内存与对应的物理内存的关系,需要牢记哪些内存是片上内存,哪些是板载内存

L1,L2 cacheline应该都是128B,由4个sector(1个sector是32B)组成,其中L1 DCache miss取到L2的cache是以sector为单位取的,cacheline的粒度和在总线上传输的粒度不一致的,参考自Pascal L1 cache
GPU一些指标
-
occupancy即占有率,这个指标描述了当前SM它的实际active warp数目比上理论warp数目的比值,有啥用呢?
在这里先说下,理论warp这个数目是与SM相关的固定的数(也与微架构相关),比如A100就是
64 warps / SM.理论occupancy是用来描述SM上warp并行的上限.warp并行,可以遮掩访存,遮掩访存,目的就是为了抵消内存墙带来的影响,对于计算密集型算子尤为关注首先来说一下啥是active warp,运行时每个时钟周期一次分配给SM的warp数目是active warp
At runtime, the number of warps allocated to a multiprocessor at once for every cycle is referred to as Active Warp
但是存在调度不均的情况导致这个理论的occupancy我们无法达到,即存在下式(一般在ncu会看到):
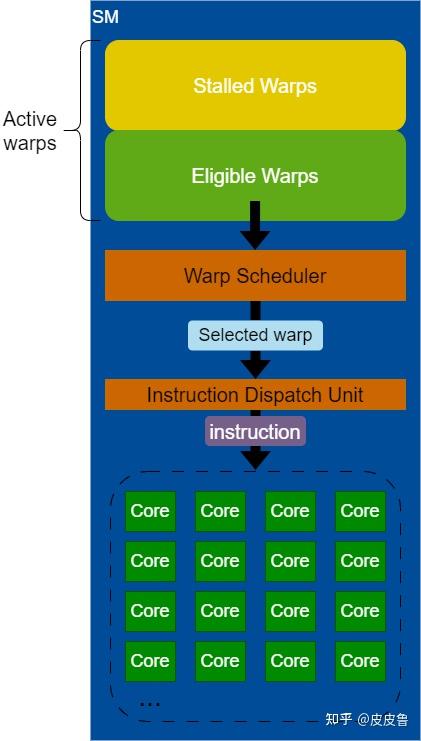
active warp可以被看做一个warp pool(或者说一个set),这个warp pool的上限就是SM相关的上限,其中的warp组成:
active warps = stalled warps + eligible warps准备好了,可以issue instruction的是eligible warps(IF了且EU空闲);而stalled warps有许多原因可能导致stalled
warp scheduler会从eligible warps这个sub-set取一个warp,叫做selected warp,发往dispatch unit,然后送到指令所需的EU去执行.下面是流程图:
stalled warp之所以stall的原因:
- pipeline busy: 指令所需计算资源繁忙;
- IF: 指令还没拿到;
- execution dependency: 存在数据依赖;
- syhchronization: 等待同步
__syncthreads() - memory dependency: bank conflict?
- …
在ncu上如何正确看待occupancy?影响因素是理论数据和实际数据组成,理论数据是
block limited sm和block limited warp,实际数据是block limited smem,block limited reg,取最小的然后优化之,同时需要注意,在volta后,sm分为4个smsp,这里体现的可能是smsp对应的理论数据参考自:
从下面开始,关于CUDA的讲解分为三个部分:硬件架构,库与函数,算子系列来进行展开,三个部分顺序不一定一一对应,可以从硬件部分开始看,也可以从算子系列开始看,遇到奇奇怪怪的函数或库在去库与函数里找解释会更好
NVCC编译流程

CUDA编译流程就像上图所示:.cu文件进行两次预处理,左边的是纯C++的,右边的是CUDA的(又或者说是host端代码和devic端代码)
device端代码预处理后会被cicc编译得到ptx代码,然后被ptxas这个汇编器得到cubin,这个过程会重复多次,看你--generate-code arch=compute_80,code=sm_80就看你前面这个virtual architecture有哪些个(虚拟架构是向后兼容的,对应的sm_xy)的情况下优化效果更好
然后把这些个.cubin弄成一个.fatbin合并了多个版本的.cubin,然后用类似内联汇编的形式经由fatbinary指令弄成fatbin.c文件.被host端代码所include的一个stub文件包含,则此刻所有代码都是.c,经由gcc编译即可,编译得到.o
多个.cu文件都过一遍上面的流程得到.o,经由nvlink(设备端的链接器)对device端代码进行链接,形成一个.o文件,然后再与原先生成的.o文件进行主机端的链接,最终形成可执行文件
上面是一坨,host端和device端一起编译,叫做whole program compilation,也可以分开编译,如下,叫做separate compilation:

分开编译特指的是设备端的代码,设备端的代码可以复用,不用都写一块,一起编译了,可以写多个.cu,跨文件去访问设备端的函数和变量.那么其中用到的这些个符号,就需要通过extern(外部函数或别的文件可见的变量)和static(用于不同文件的同名变量)关键字来修饰其可见性了,这时最好用引用而非具体的变量名
whole program compilation的nvlink不是用于设备端的链接器吗?确实看到了:
CUDA programs are compiled in the whole program compilation mode by default, i.e., the device code cannot reference an entity from a separate file. In the whole program compilation mode, device link steps have no effect. For more information on the separate compilation and the whole program compilation, see Using Separate Compilation in CUDA.
那这是真的没用吗?(@_@;)还是说后面改了

2stage的编译过程,编译出来的是可以直接在CUDA Runtime上执行的二进制代码
From this it follows that the virtual architecture should always be chosen as low as possible, thereby maximizing the actual GPUs to run on. The real architecture should be chosen as high as possible (assuming that this always generates better code), but this is only possible with knowledge of the actual GPUs on which the application is expected to run on.

1stage的编译过程,得到了对应的ptx代码,运行的时候驱动取得了确定的GPU型号,再进行编译运行,这又称之为JIT Compilation(Just In Time,即时编译),通过--generate-code arch=compute_80,code=compute_80.对于某一些功能以及性能的追求,可以用这个,因为知道了具体的gpu型号可以生成最匹配的二进制代码
By specifying a virtual code architecture instead of a real GPU,
nvccpostpones the assembly of PTX code until application runtime, at which time the target GPU is exactly known.
参考文件:
硬件架构
Pascal前架构
Volta
微架构
CUDA的微架构一般指的是SM,不包括外围的辅助功能;
CUDA指令集:SASS(Streaming ASSembly);还有个在SASS之上的虚拟中间代码指令集PTX(Parallel Thread eXecution);
GPU所有指令都是从SM发出的
CUDA用Compute Capability(简称CC)来区分各个微架构,比如5.0,6.1,7.5,…通常用SM_50,SM_61,SM_75(有时也没有下划线)来表示
CC有大版本和小版本,大版本一般有代号,比如3.x叫做Kepler,5.x叫做Maxwell,6.x叫Pascal,7.x没有统一代号,7.0是Volta,7.5是Turning,ampere卡是8.0
CC和SASS指令集有比较直接的对应关系
很多指令的throughput和latency都与CC有关
CC只与设备的SM架构版本有关,与设备绝对算力的强弱无关
PyTorch中的CPP/CUDA扩展
pytorch中调用cpp/cuda扩展有预编译和**即时编译(JIT)**两种模式
-
预编译
通过一种神奇的方法将CPP/CUDA代码编译并构建成模块,从而可以在python代码中用上自己写的算子~
-
基于预编译的扩展,望文生义👀,它是需要"编译"的,
setup.py是一个基于setuptools的编译脚本,需要编写它,以指明实际需要编译的扩展(模块名也是在这个脚本中被指定的).在这个脚本,可以指明**CppExtension和CUDAExtension**这两种不同的扩展,以适配不同的机子,还可以指明扩展的名字,扫描头文件的路径,库的路径,等等.通过这个脚本,我们会形成最终的nvcc/g++命令,对扩展文件进行编译最终执行指令以进行编译:
python setup.py build_ext --inplace,生成xxx.so在当前目录,可以直接import xxx这个动态库一个
setup.py的模板👀1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# setup.py
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension,CUDAExtension
setup(
name = '', # 包名(但是好像没有自动生成)
ext_modules = [
CUDAExtension(
name = '', # 扩展模块名,即py中调用时import的那个module name
sources = [''], # 源文件 可以用glob.glob()找到match的文件
include_dirs = [], # 头文件搜索路径
extra_complile_args = {'cxx':['-g'], # 其他编译选项
'nvcc':['-O2'],})
],
cmdclass = {'build_ext':BuildExtension}
)注:
python setup.py后面的build_ext --inplace是干啥的呢?可以把build_ext理解成是构建这么一个扩展模块;而--inplace则是编译后的扩展模块放在当前的目录中?
-
扩展文件被编译了,即形成了二进制文件,这个二进制文件在python中是怎么调用到它的呢?通过pybind11这个库来实现的,它是一个用来在c++代码中创建python的连接的库.宏定义**
PYBIND11_MODULE**为c++代码接入python解释器提供了入口1
2
3PYBIND11_MODULE(TORCH_EXTENTION_NAME,m){ // TORCH_EXTENSION_NAME是模块名称 // m是模块实例
m.def("",,,py::arg(),);
}TORCH_EXTENTION_NAME是在setup.py脚本中的扩展模块名(即python中的module名),对应的是编译命令中的-DTORCH_EXTENTION_NAME=...这个宏m是扩展模块的实例,{}中的每个m.def都定义了一个扩展模块的成员函数,一般形式为:m.def("python调用函数名",cpp具体函数的函数指针,"帮助文档的说明",参数列表用以关键字传参)
在利用pybind11将c++代码绑定到python时,需要
#include <torch/extension.h>,原因见下方:
-
-
即时编译
通过
torch.utils.cpp_extension下的load函数即可实现即时编译,以下是一个模板(详细信息看这个篇章的最后一个参考文件):1
2from torch.utils.cpp_extension import load
module_name = load(name="module_name",sources=['xxx.cpp','xxx.cu'],)
在PyTorch中增加CPP/CUDA扩展的操作说完了,但是我们知道PyTorch中有个很常用到的数据类型叫**Tensor**,那我们在CPP/CUDA扩展中怎么模拟或者说有没有得直接使用这个数据结构呢?
我们可以通过#include <torch/extension.h>就可以在扩展中调用所有PyTorch支持的功能.有三大命名空间:c10(Caffe Tensor Library),at(A Tensor Library),torch.翻看别人项目或是算子的源码,多用的是torch这个namespace
注:在使用预编译的方式引入cpp扩展时,需要注意setup.py脚本内的要编译的文件它的名称不能一样,比如[xxx.cu,xxx.cpp,xxx.cc]是不被允许的,用JIT编译则可以,但是预编译会报错,改成不同名字即可,比如[x.cu,xx.cpp,xxx.cc]
一些nvcc编译选项
--expt-relaxed-constexpr更宽松的constexpr,使得host端可以调device端的constexpr修饰的函数,device端也可以调用host端的constexpr修饰的函数;nvcc在编译时会定义宏__CUDACC_RELAXED_CONSTEXPR__当设置了这个标志;--expt-extended-lambda或--extended-lambda扩展的lambda表达式,可以在__host__或__host__ __device__执行空间下的函数内定义扩展的lambda表达式,显式的写出__device__或__host__ __device__在lambda表达式[] 这里 {}; 这玩意具体啥场景下用暂不清楚,看别人的编译选项有,就记下来了,感觉会有用,说是可以用在__global__函数模板实例化的实参中🤔--use_fast_math:使用快速数学库,设置以下几个标志位:--ftz=true非规格数直接置0,false则保留之;--prec-div=false采用快速逼近而非true时的round-to-nearest.用于控制除法和倒数;--prec-sqrt=false同上,这是控制平方根的;--fmad=true启用浮点乘法和浮点加法变为浮点乘加,应该是引导编译器用fma优化的
参考文件:
- PyTorch 源码解读之 cpp_extension
- Pytorch+cpp/cuda extension
- PyTorch_CPP_API_CLASS_TENSOR
- PyTorch_CPP_API
- Python打包分发工具setuptools
- build_ext --inplace 是什么意思
- vscode配置<torch/extension.h>的include path
- writing-a-c-extension
- cpp_extension_doc
- nvcc-compile-option-relaxed-constexpr
- nvcc-compile-option-extended-lambda
- nvcc-compile-option-use_fast_math
PyTorch Profiler
把自己的算子引入了torch,如何与torch原生的算子进行性能分析呢?可以利用torch的profiler工具:torch.autograd.profiler
待补充
参考文件:
库与函数
cublas_v2
这里主要说下cublas咋用,以及会遇到的问题,以cublasSgemm为例:
1 | |
在提及具体的函数使用前,首先说下元素排放的问题
cublas中的元素存储是列主序排放的(沿袭了Fortran的老习惯),那我们是以行主序构建的矩阵,怎么让cublas正确理解呢:
我们知道比如一个6个float的元素,排在数组里:[0,1,2,3,4,5]
-
给它弄成2x3的行主序矩阵:[[0,1,2],[3,4,5]];
1
20 1 2
3 4 5 -
给它弄成2x3的列主序矩阵:[[0,2,4],[1,3,5]];
1
20 2 4
1 3 5 -
给它弄成3x2的列主序矩阵:[[0,3],[1,4],[2,5]],则此时是行主序阵的转置
1
2
30 3
1 4
2 5
显然,,列主序的阵A和我们行主序阵A的转置,理解起来是一样的
以下给出两个方案,在调用cublasSgemm时以得到期望的结果
-
方案一
因此在传参的时候可以利用这种方法给它弄成,这样计算结果C阵就是原来阵的转置根据上面的式子可以理解为是传入的,是传入的,则有:
: m,n,k
: n,m,k
也要把ld也换成对应的,这里lda=n;ldb=k;ldc=n由于C阵得到的是转置的,那我们直接拿出来按行主序读,就直接是符合预期结果的!
-
方案二
如果不想像上面操作,觉得有点绕,也可以将cublasSgemm的cublasOperation_t transa和transb给它开起来:CUBLAS_OP_T(不转是CUBLAS_OP_N)
这样做,我们就把行主序的,转置了,那实际上恰巧就是列主序的cuBLAS的阅读顺序,同时需要注意,此时的lda,ldb,ldc传入的是转置后的行数 ,即lda=k;ldb=n,ldc没有转,则为ldc=m;需要注意,得到的C阵是按列主序排的,因此我们外面需要手动给它转置一次,或者按列主序的方式把数据对应着读出
注意: 在调用cublasSgemv的时候要注意row和col需要调换,因为对A的转置会影响到向量x和向量y
参考文件
cusparse
参考文件
线程束shuffle指令优化
线程束洗牌(shuffle)指令是线程束内线程通信的极佳方式:延迟极低,不消耗内存,通过束内线程相互访问寄存器以传递数据,不用再走共享内存乃至全局内存
laneID(束内索引),就是一个线程束内线程的索引;warpID,表示线程束的ID
利用block内线程号分别/32,%32来获得warpID,laneID
shuffle指令分为用于整型和浮点型
-
整型
int __shfl_sync(unsigned int mask,int var,int srcLane,int width=warpSize)
mask指示width大小内的线程有哪些线程参与运算;width缺省值是32,即一个warp的大小,它可以取值为2,4,8,16,32;比如mask取0xffffffff,表示32个线程都参与运算,如果LSB取0则表示0号线程不参与计算;var表示当前线程提供的值;srcLane是进行广播的laneID,它广播的值通过返回值承接具体来说,比如
srcLane选3,就是把线程束内 (之所以是线程束内,是因为默认的width是warpSize,是不是线程束内要看这个width,不然就是width+srcLane作为偏移值,比如width是16,则srcLane对于[0,15]是3,对于[16,31]是19(3+16)) 束内线程索引为3的变量var的值进行广播,给width内的所有线程;注: 个人感觉这个width更像是分组,默认warpSize为一组,当然你想自定义也OK,就设置它的值(2,4,8,16,32这几个数里选).同时需要注意,这个srcLane本质上应该是
srcLane=srcLane%width,它可以做到环绕移动(通过srcLane= threadIdx.x+offset使得整个width内的数一起转圈圈,转的步数是offset) -
int __shfl_up_sync(unsigned int mask,int var,unsigned int delta,int width=warpSize)
这个函数取的值是:当前调用线程的束内线程编号减去delta编号的线程的var值,如果变负值(取的数的束内线程号)则保持原来自己的值;注: 叫up可能是因为前面的束内线程把值往前给
-
int __shfl_down_sync(unsigned int mask,int var,unsigned int delta,int width=warpSize)
上面的反转版,这里变成了调用线程的束内线程号+delta(warpId + delta),从这个束内线程号取值,当然如果越了width,则保持原值;注: 叫down可能是因为后面的束内线程把值往后给
-
int __shfl_xor_sync(unsigned int mask,int var, int laneMask,int width=warpSize)
这个指令很神奇,调用线程的束内线程号和laneMask值做异或,得到的就是目标线程的束内线程号,然后目标线程会把它的var通过返回值给调用线程
之所以说神奇,是因为laneMask比如取1,得到的是butterfly exchange
-
-
浮点型
无需改函数名,已有重载,只需把var的int改成float即可
以下给出示例代码,其中使用了__shfl_xor_sync()指令来对一个总长度为32的数组,每个线程管理长度为4的数组做一个laneMask=0x00000001的大蝴蝶交换
1 | |
实验结果如下:

注: 上面的代码中的__shfl_xor()一类的函数,在CUDA11.x上进行编译的时候报warning,说要用__shfl_xor_sync()
算子系列
reduce
reduce即为所说的规约操作,较为正式的说法是在一串数据中采用满足结合律的二元操作符最终得到一个结果,而这个操作符一般是求和,求均值,求最大最小值.下面以求和操作为例
通俗的说就是给定一个长度为n的数组,对n个数进行累加,得到的结果便是规约的结果
GEMM
分块+双缓冲+smem bank conlift+register bank conflict[待解决]
GEMM的优化主要有两个思想:分块以及双缓冲,同时在其中对A阵进行打包,并采用向量化访存.做到上述这些操作,已经可以达到cuBLAS的**93%**了.在讨论具体怎么做前,回顾下最朴素的做法:
朴素的做法是一个线程处理阵的一个元素,这需要访问global memory:次,很明显,你得频繁访问global memory,这是latency最大的一层存储,这样的开销很大
分块思路
我们应该尽量利用GPU的global memory - shared memory - register的存储结构进行分块存储

按照上图进行划分,1个block处理大小的阵(黄方格),我们可以把A阵的的小矩阵和B阵的的小矩阵(浅蓝块)移动到shared memory上,这样整个C阵被划分为:个block,每个block需要访问global memory 次,化简一下可得:
因此可知,此时的访问global memory的次数为:.可见,随着和的变大,访问global memory的次数越少
目前来说,一般是将和均取值为128,则取值为8(为什么这样取值啊❓)
那既然我们可以把数据腾挪到shared memory上,如果移到register岂不更快,由此我们对黄方格进一步划分(以下针对block进行讨论),我们让1个线程处理大小的矩阵.则此时我们可以计算下如果不对进行分块,依旧是每个线程处理黄方格的一个元素,则需要访问shared memory的次数为:,而进行分块后,一共有个线程,每个线程需要访问shared memory次数为:,则该block访问shared memory的次数为:,显然随着和的增大,单个block访问shared memory的次数会变少
根据经验和均取8(为啥?)
梳理一下上面的信息:我们为了减少访问global memory以及shared memory的次数,对C矩阵进行了两次分块,分别将数据搬运到shared memory和register上去,一次的数据搬运量分别是$b_m * b_k $ + (这是对于block的,将数据搬运到smem上去); + (这是对于thread的,将数据从smem搬运到自己的register上去),而我们给出了详细的参数配置:,,由此可以计算出来一个block里的线程数目是,共计256个线程
计算正确性
谈论完分块,谈论一下计算的准确性,因为分块后的计算你得算得对才有意义,不然优化得再快也没用.
从外部来看,我们的黄方格是由多个对应的浅蓝块进行外积累加而成(上图左侧);而黄方格内部是通过每个线程计算对应的深绿块得到的,而深绿块是通过对应的天蓝色块的外积累加而成.由此得到的深绿色块是符合计算原理的,而由深绿色块组成的黄方格也是符合计算原理的,因此整个计算过程是可以得到与内积相同的结果,具备计算的正确性
如何搬运所需的数据
那计算是正确的,就要想想分块后的数据应该怎么拿到:
首先是怎么把数据从global memory搬运到shared memory上的,目前我所使用的是V100,得绕一圈才能把数据放到shared memory上:从global memory经由register再放到shared memory上,因此每个block内的线程就需要各自负责对应的数据搬运,把计算所需的A分块的和B分块的搬运到临时的寄存器区域存储,然后放到共享内存去
这其中可以利用float4来进行向量化访存,同时A阵搬到reg后,再搬回smem时,可以做手动转置,以便于后续reg访问smem时可以利用向量化访存来获取数据;B阵则直接搬到reg,不用转置,直接存回smem即可

那么smem到reg中的数据,则是由每个线程从共享内存中取对应的数据,下图中展示的是block内的0号线程,它需要取左边的在smem上的A阵的8个元素,需要取右边的在smem上的B阵的8个元素,由于smem上的A阵已经转置了,所以可以理解为它重排成按列存储,然后沿着箭头的方向进行迭代,则可以算出0号线程负责的8x8矩阵的值

进行双缓冲
如果按照上面的方式,我们需要定位到当前这个block负责的区域:tmpA和tmpB;
然后在大迭代中( -> 的迭代)先将数据搬运到smem上,然后再在小迭代中(每个线程1列数据和1行数据,直到滑到)把数据从smem搬运到reg上,然后再计算出对应的8x8阵,并累加;
可以看出,这样的计算方式并不能很好的发挥出计算单元的性能,因为你每次都得取当前要用的数据,然后再计算;
因此可以用双缓冲来处理这个问题:每次预取下一轮要计算的数据,然后当前要用的数据已经准备好了,即整个流程变为:
- 预取数据,放入smem和reg中,需要注意,我们的数组开了原先的两倍,用于分别存储下一轮要用的数据和当前轮使用的数据;
- 大迭代中先预取下一轮SMEM的数据;
- 小迭代中预取下一次计算的数据,放入reg中;
- 小迭代计算
- 直到大迭代计算完毕,则将数据存回C阵对应的区域中(tmpC)
为什么双缓冲这种机制会被支持呢?因为ld/st单元和计算的单元是两个不同的部件
当我们根据上述的做法进行优化后,我们自制的sgemm可达cuBLAS的93%
smem bank conflict解决
我们知道在定义一个block内线程数目的时候是16x16,即blockDim.x和blockDim.y均为16,这256个线程共需要8个warp,这8个warp根据朴素的思路是按照:
1 | |
这样的方式排列的.然后我们在用线程去处理值的时候(即把smem中的数据移到reg),是通过tx,ty(threadIdx.x,threadIdx.y)来处理的,并且如0号线程它连续取8个元素(A阵和B阵各八个),以B阵来说,那4号线程就会取到32-39这八个元素,因为是采用float4,即LDS.128的方式进行向量化访存,则T0-T7属于一个quarter warp,它里面的元素会发生一个2 way bank conflict,显然我们应该消除这个smem bank conflict带来的更长的访存时间;
需要知道,warp内部的排序,并不是按照上述朴素思路那样规规矩矩进行排列的,我们只需要在x和y这俩方向上各排够16个线程即可,warp内部的顺序,可以是朴素思路的那种规规矩矩2x8的排列,也可以是根据优化需要自己编排出来的如4x8/8x4的warp内线程排布方式,你只要按照你排布的方式去获取值,就会得到正确的结果
因此我们将warp内的排布形式变成下图所示:
1 | |
当我们按照这种z-order式以8x4的形式排列warp内部线程的时候,我们可以将整个warp的memory transaction由原先的8个变为2个(对B而言),减少了访存的时间开销
因此在这种warp内部的排列下,将8个warp排好,如下:
1 | |
则满足了x和y方向上的线程各16的要求,然后求出对应的warpId和laneId,取对应的值进行计算,不过需要注意,这里我们把内部的8x8拆成了4个4x4计算,如下图示:

当解决了shared memory bank conflict之后,我们的性能就能达到cuBLAS的95.6%了(M=N=K=4096)
为什么会存在bank conflict呢?
为了实现并行访存,要实现多端口读写的能力,但如果不分bank,会使得布线非常困难(感觉布线太大影响散热,就得拉开位置,延时感觉也会变大),因此分bank,地址按4字节对齐[0,4,...,124,128,...],对128取余(4B粒度常用,warp==32thr,128Byte为1个整体,32个访存端口),余数相同则为同一bank,那同一bank,同一访存端口,无法在同一cycle实现访存,故得拆成串行的
参考文件: 5.1 规避共享内存 Bank 冲突
register bank conflict
暂时没有胆量去碰触SASS,还在积累,希望能看懂PTX和SASS
这里简要说一下什么是register bank conflict,以便于我有朝一日突然兴起把这个给处理了
在Volta架构以前,我们每个SM上的RegisterFile是被分为4个bank的,对于Maxwell和Pascal架构而言,寄存器id%4得到的就是bank的id,当一条指令的源寄存器有2个以上来自同一bank,就会发生register的bank conflict,浪费1个cycle以重发射指令;
而在Volta架构开始,SM的RegisterFile被分为2个bank,只有当源寄存器id全为偶数或是奇数才会有bank conflict(?bank conflict为何会有这个东西(有的说是资源抢占问题(会影响到整体的并行性),有的说是一个cycle吞吐4B(指smem)),且2way bank和4way bank的bank conflict发生情况为何不同?)
针对于register bank conflict的解决方案有两点:
-
寄存器重映射
重映射就是改变了原架构默认的register到bank的映射方式(这玩意要动哪个东西?好奇) -
FFMA顺序的调整
进一步处理上述未处理完毕的寄存器bank conflict问题,通过指令重排来实现,并辅以reuse这个control code,类似于将某一个寄存器放进reuse cache,然后下一轮从reuse cache中获取,而避免了register的bank conflict这一步是在sass汇编上进行操作的,操作完毕之后,找个大佬实现的汇编器给它生成机器码
GEMV
SPMV
SpMV,即稀疏矩阵向量乘,在cuSPARSE中它的公式形式是,我们自己写的时候和直接用1.0f,0.0f;
稀疏矩阵A乘于稠密的x,得到稠密的y,这是SpMV的描述,跟上面写过的gemv不同的地方在于A阵是稀疏的了,那稀疏的A阵,就代表它里面的非零元素很少,那要用稀疏格式来进行存储,这里采用的是csr来存储
CSR
CSR全称为Compressed Spared Row,具体的含义如下图示,可以这么理解,采用csr格式进行稀疏矩阵的存储,我们需要三个指针:row offset, column idx, values
values存储的是稀疏阵中的非零元素,是以行主序的方式对稀疏阵非零元素进行获取,size是非零元素的个数;column idx存储的是values中对应的非零元素的列索引,显然这会在我们与x进行乘法操作时用上,size是非零元素的个数;row offset用于存储稀疏阵中每行第一次遇到的非零元素的在values中的索引,它的size是行数+1,最后一位表示的是非零元素的个数

那么这些稀疏阵,要在哪里获取呢 -> 稀疏阵大全
nsight system基础使用
nsight compute基础介绍
这里对ncu这个工具的一些指标组成做个笼统的介绍,以便于可以看懂metric的组成,在看别人的.sh或是Makefile里的一些指标可以看懂,具体细节还是查ncu文档
之于counter而言,有两种峰值速率
- burst rate
- sustained rate
这些峰值速率可以用来算throughput的百分比
在ncu中,所有性能计数器都叫指标,但可进一步分组,组内的有特定的属性
While in NVIDIA Nsight Compute, all performance counters are named metrics, they can be split further into groups with specific properties.
metrics entities
-
counters
可以是来自GPU的原始计数器,也可以是计算得出的计数器值。每个计数器下有四个子指标(sub-metrics),也称为汇总指标(roll-ups metric):
.sum,.avg,.min,.max
汇总指标也有内置的sub metrics,分为active(单元活动周期)和elapsed(单元运行周期)的peak_sustained(峰值持续速率),number of operations(操作数量),峰值持续速率的百分比 -
ratios
包含三个子指标:
.pct(百分比表示的值);.ratio(比率表示的值);.max_rate(比率的最高值) -
throughputs
表示GPU的某一部分接近峰值速率的程度。有子指标如下,针对active和elapsed的peak_sustained的pct
metrics naming conventions
unit-level的counter组成如下:unit__(subunit?)_(pipestage?)_quantity_(qualifiers?)
interface的counter组成如下:unit__(subunit?)_(pipestage?)_(interface)_quantity_(qualifiers?)
- unit-level的counter指的是gpu逻辑或物理的unit;
- interface的counter是具备
sender2receiver形式的,有俩unit,一个sender一个receiver;
它们的metric就是由counter名称结合汇总指标:(counter_name).(rollup_metric)或者再.到汇总指标的子指标(counter_name).(rollup_metric).(submetric)
其中上面带问号项的有可能有,有可能没有
具体项的细节建议看metrics decoder部分的表格,单看定义不大好看懂
metrics decoder
这一章里面对上述命名规则的几个部分,如unit,subunit,pipeline,quantity详细罗列并介绍了,可以去官网上看
metrics reference
这里的metric不遵循上面的命名规则,有需要单独看
NVRTC 未看
nvdia runtime compilation
NVRTC is a runtime compilation library for CUDA C++. It accepts CUDA C++ source code in character string form and creates handles that can be used to obtain the PTX. The PTX string generated by NVRTC can be loaded by cuModuleLoadData and cuModuleLoadDataEx, and linked with other modules by using the nvJitLink library or using cuLinkAddData of the CUDA Driver API. This facility can often provide optimizations and performance not possible in a purely offline static compilation.
Volta后代SM微架构
写给自己:
这一系列需要补充,补充SMSP(SM sub-partition / SM processing block / SM sub-core),补充真正的微架构信息,从sub-core出发,对里面的LD/ST单元进行全面审视,实际sub-core是warp-scheduler(1 warp inst/clk)对访存指令发送至MIO Queue,后发送至MIO Scheduler,4个sub-core争用共享内存
同时对warp scheduler的静态warp pool做分析(size(warp pool)就是active warp),其中的eligible warp们是不会stall的
同时对gpu顺序执行做解释
参考文章:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!