review-CS-basic-knowledge
本文最后更新于:8 个月前
C++智能指针
参考资料:
总线相关
CPU内部和cache是通过本地总线(local bus,又叫后端总线)连接的,而访存是通过接口连上系统总线,系统总线又连上IO桥接器(北桥芯片),桥接器一端是IO总线,一端是内存总线(又叫前端总线)

- 北桥芯片主要控制CPU内存显卡等高速设备
- 后南桥芯片被加入,是用来负责IO总线之间的通信

参考资料:
CPU的三级缓存
CPU的三级缓存:L1Cache,L2Cache,L3Cache
其中L1,L2是核心(core)内的缓存,而L3则是多核心共用的缓存,也在片内
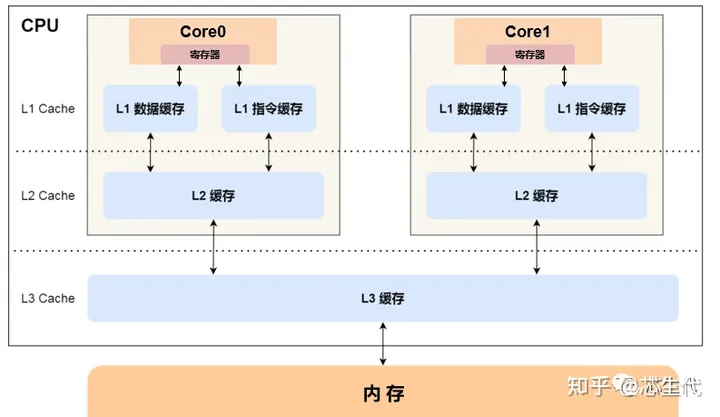
L1Cache是分离缓存,分为L1 D-Cache和L1 I-Cache可以避免访存冲突(总不可能流水线处理的时候IF和MEM这俩个流水段打起来吧)
L2Cache则变为统一缓存,毕竟分离缓存的size不好掌握,cache资源又宝贵,如果分离的话,又cache没用满就吃亏了

从单核的缓存一致性来讲,有**写直达(Write through)和写回(Write back)**两种策略来确保缓存一致性
- Write through无论你这个更新的数据在不在cache内都得写回内存;
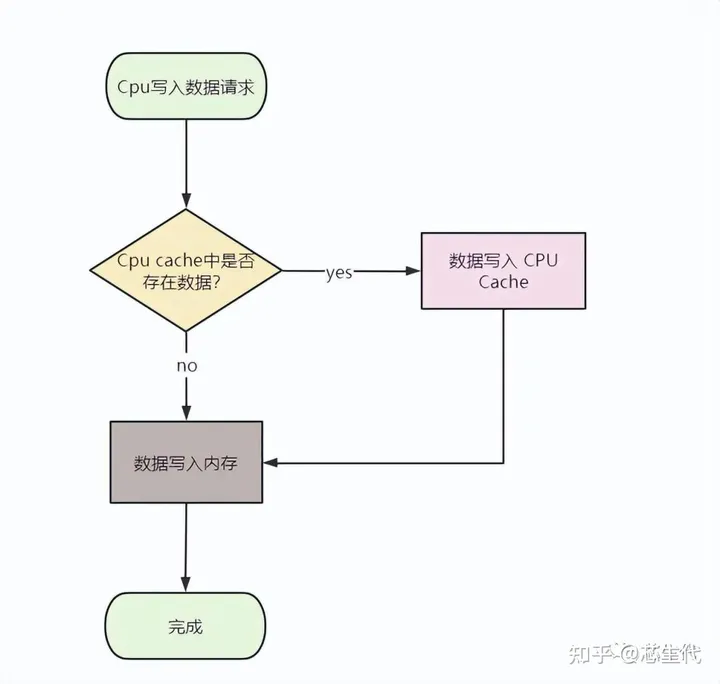
- Write back则是多了个dirty标志位,标识cache line中的数据和内存中的是否一致,不过这会使得读cache line进去,且cache已满,且交换出去的cache块是dirty的,就要执行一次写操作

参考资料:
- 一文吃透CPU三级缓存 只讲了单个核心的缓存一致性问题,对于多个核心的缓存一致性问题没有描述
- 我把 CPU 三级缓存的秘密,藏在这 8 张图里
内存对齐
C语言的存储层次
参考资料:
虚拟内存
关于虚存,每个进程都有虚存,比如32位的os就给每个进程弄个4GB的虚存,用虚存可以相较于用真实的物理地址:
- 可以给人制造扩大内存的假象(无限大),规避内存不足的问题(当然如果真的物理内存不足了,就会通过内存页面置换策略,把久没用到的页帧放到swap分区里面,然后把要用的页帧替上去,不过这个过程涉及到硬盘读取,slow);
- 然后也不存在同时访问同一地址修改造成的数据冲突;
- 也可以对碎片化的内存进行使用;
通过MMU(Memory Management Unit)这个部件来实现VA -> PA(CPU收到VA交给它翻译成PA),它是通过TLB(快表)和页表(Page Table)这俩个表来实现VA->PA的(页表是放在进程的内存里面的),TLB里面放置的是Page Table的常用页表项(局部性原理)
这俩表里面放的都是叫做"页表项"的东东,是VA->PA的映射
每个物理页和虚拟页是大小相等的4KB,它们的映射关系就是一对页表项
什么时候会出现缺页异常呢?显然是在我们的TLB和Page Table都找不到映射关系或没有权限,就报异常(Page Fault)了,而这个异常,会让你的CPU读不到数据,它就罢工,进程就出现了缺页中断,用户态就切换到了内核态,就交由内核的PageFaultHandler来处理:
分三类缺页中断:
- Hard Page Fault/Major Page Fault: 就是找不到这个映射关系了(页帧),要CPU去打开磁盘设备读取到物理内存中,再让MMU建立VA->PA的映射关系;
- Soft Page Fault/Minor Page Fault: 实际上物理内存有这个页帧,是被别的进程调入的,我们这个进程不知道而已.只需要MMU建立VA->PA的映射关系即可.(一般出现在多进程共享内存区域);
- Invalid Page Fault: 内存地址越界,解空指针引用,权限问题,那么内核就会报Segment Fault,中断你的进程(挂掉你的进程)
内存的惰性分配(或者叫延时分配),malloc并无真正分配,只是用到你申请的物理内存时,发现没有才会启动申请,这期间就会出现Page Fault
参考资料:
死锁
死锁的四个必要条件:
- 互斥
- 占有并等待
- 不可抢占
- 循环等待
避免死锁的方法:
-
死锁预防,破坏以上后三种条件(因为是非共享资源,互斥是必须的);
-
避免死锁,开始前判断,只允许不会产生死锁的进程申请资源,主要是银行家算法
-
死锁的检测和解除,检测到运行系统进入死锁,进行恢复(抢占资源/终止进程(全部终止和逐个终止))
参考文件:
计算机中的浮点数
浮点数在计算机中通过S(Signed),E(Exponent),M(Mantissa),即符号位,指数/阶码,尾数三者来表示.表示出来的浮点数类型有以下三种:
- 规格化浮点数
- 非规格化浮点数(非常接近0的数以及0)
- 特殊的数(±infinity以及NAN)
这三类数如何区分的呢?
规格化浮点数的指数部分不能够取到全0或全1,只能取其中的部分,全0则跳到了非规格化浮点数,全1则跳到了特殊的数
规格数
此外,以FP32为例,E8M23,则意味着它的指数位是[0000 0000,1111 1111]这么一个范围,显然你如果这样取,取到的指数为都是的,即范围是[0,255],为了让指数位平均分配在和之间,提出了一个exponent bias,它的计算公式是:,这里就是127,因此指数的取值范围落在了[-127,128].实际上,应该是[-126,128],为了实现逐渐溢出的特性,非规格数的指数数值的计算方式与别的不同
对于规格化浮点数来说,它的取值很平庸,由符号位决定正负,由指数位决定范围,由尾数位决定精度,表示了浮点数中的绝大部分数,但是它无法表示很小的数以及0,也无法表示infinity,它的取数是在±[1,2) ** [-126,127] 这里写得很简略,都是区间,从左到右依次包括了S,M,E
非规格数
非规格数的特点是阶码全取0
其中规格化浮点数和非规格化浮点数的区别在于两个:
- 隐藏的前置1 or 0
- 阶码所表示的值是阶码对应的十进制位减去exponent bias,或是1 - exponent bias(阶码全是0)
其中关于第二点,之所以不采取和规格化数一样的计算方式,是因为为了让规格化数的最小值和非规格化数的最大值,可以紧密的衔接在一起,通过这种溢出的思想,由非规格化数丝滑连接到规格化数
再通过一种抽象的方式表示非规格化数的范围:±[0,1) ** (-126),这里的0,1表示的是不同尾数的取值导致的,显然尾数取全0就是正负零,取全1,就是此刻的最大值,但由于非规格数前置为0因此到不了1,只是一个很大的很接近1的数,然后再乘于对应的指数(对于非规格数而言,指数就是1-exponent_bias)
特殊的数
特殊的数的特点是exponent全取1,当尾数全零,则根据符号位来区分正无穷还是负无穷;否则则为NAN
可以通过以下表格查看三者分布:

特别注意: N卡的一些数据类型不遵循IEEE754标准嗷,比如FP8的一个E4M3的类型,它为了取值更大,规格数可以取到448(1.110(2) * 28),舍弃了精度,与754的规格数阶码不能全1相反,它阶码全1了,尾数的最后一位空了出来
参考文件:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!