RISC-V汇编知识
本文最后更新于:1 年前
写在开头
在大致查阅了网上社交媒体的一些关于主流芯片的架构的评价后,x86,arm,RISC-V这三个讨论热度最大.其中x86比较闭塞,且从8086出发,学习成本略高,冗余度也高(有部分内容在后续芯片设计开发中被废弃);arm的话生态最好,但是指令集授权(虽然也不是我该关心的事😂)比较hard,有些厂商没有v9的架构,只能用v8一套的生态,但是ARM架构的芯片有应用于PC的(MAC),也有应用移动设备上的,总体前景和生态是优于x86的;RISC-V的话开源,简单,且UC Berkeley在cs61c的课程中教授的就是这个芯片架构及指令集,国内浙大也跟着开授了相关的课程;
因此决定先从RISC-V学习起一些基础的汇编知识,然后再转到ARMv8上,主体的学习成本依旧放在ARMv8上,RISC-V只是作为汇编初入门的一个过渡阶段,以及对体系结构知识的温习;
关于之前学习的x86下的intrinsic编程,其实在arm中的neon intrinsic也是有类似的知识,知识总是具有相通性,因此也不能说之前如SSE,AVX的编程知识就废弃了,从某种意义上说,思想本质是一样的.借用浮点寄存器/向量寄存器去做SIMD,不过相关的命名规范,指令名称一类的换个样子适配到arm架构上去罢了.也算是一种知识迁移吧~
与别的ISA不同之处
RISC-V与别的指令集架构不同之处在于,它被设计为模块化ISA,而如x86是增量ISA
增量ISA:在支持原有的指令集的基础上增加新的指令和功能,就是向下兼容的意思(那感觉操作码的位置空间都被占的差不多了…)
模块化ISA:由1个基本的整数指令集(如RV32I/RV64I)+可选的扩展指令集

注意:在下文的讨论中,我们所采用的基础指令集是RV32I,关于扩展指令集,本文不涉及
如果想要使用mul,div,rem表示乘,除,取余操作,这些需要加上扩展指令集M才可以用,即RV32IM
单位度量
在RISC-V中,一个字节是8位,16位的被称作半字,32位则称作字(word),64位则是双字
注意:在8086的学习中,关于堆栈段里涉及到的字(word)这个的大小是2个字节,所以不同的处理器架构乃至说不同的生态,在一些没有统一定论的数据格式的规范上,是很混乱的,所以这些东西遇到了要查一查文档。
寄存器
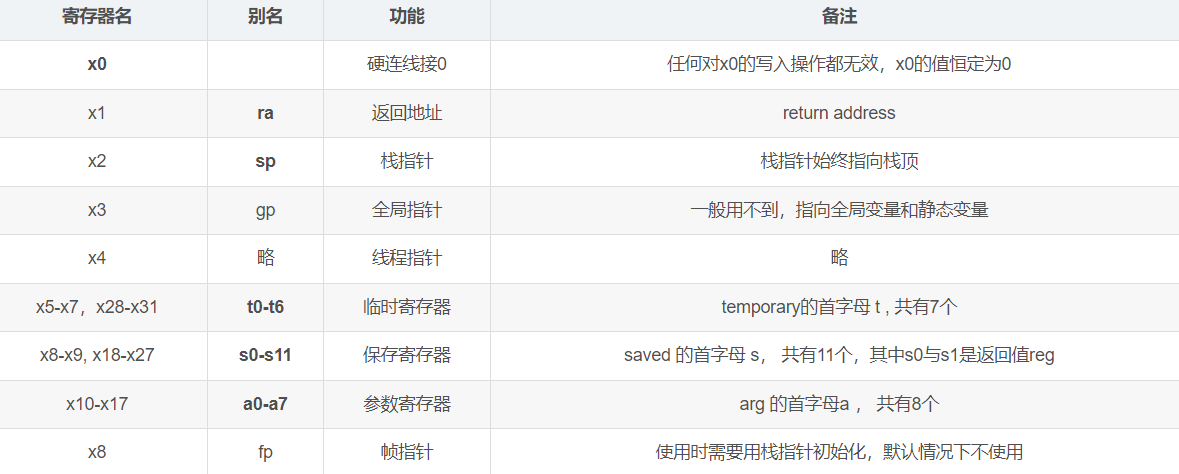
采用32位寄存器(RV32I),有32个,常用别名(一般用别名,有特殊含义)见下表:
一般在进行数据传输的时候,若是把一个字节的数搬到寄存器中去的话,需要做符号位扩展,即需要将8位的数扩展为32位,且不改变数值本身的大小.在计算机中是以补码存储,比如(-2)=(10000010)b的补码形式为(11111110)b将其扩展为32为则是用符号位补足剩余的位数(11111111 11111111 11111111 11111110)b,则成功扩展,对补码取补码即得原码,可见依旧是-2
操作码
先给出RV32I的指令集指令表,方便后续查看(其实指令条数不多)
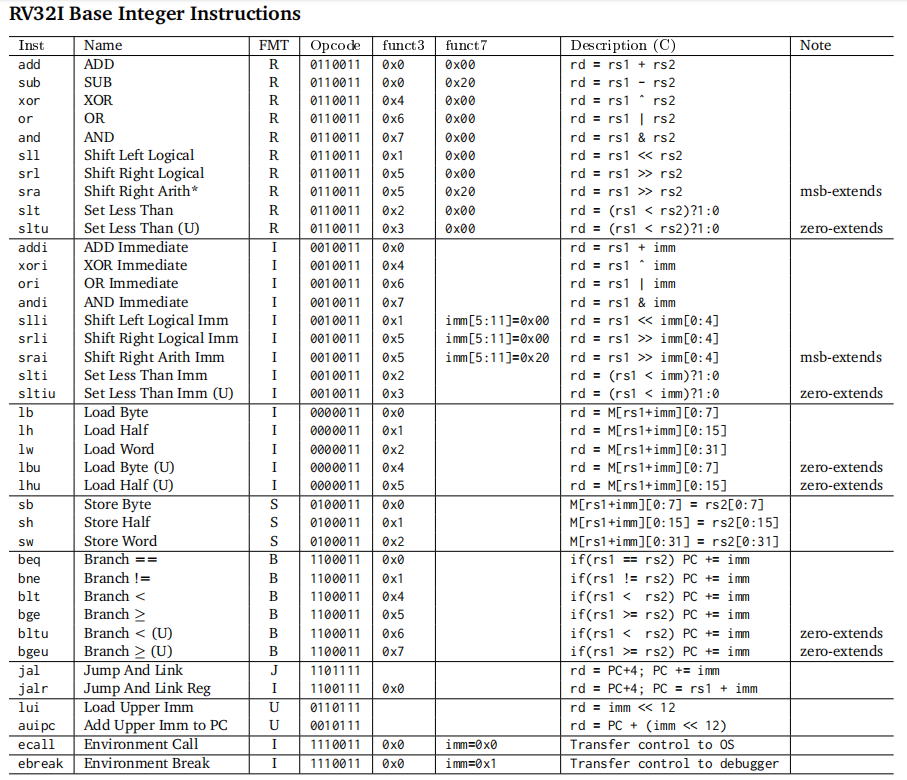
注释中说的zero-extends指的是零扩展,msb-extends指的是最高有效位扩展(符号位扩展)
指令
在RISC-V中,一般涉及到多个寄存器的操作时,第一个寄存器一般都是目标寄存器
RISC-V的指令集很清晰,它都是一些明确语义的英文单词的首字母拼接而成,如分支指令的bne,表示branch not equal
RISC-V指令集针对不足32位的数的写入会做符号位扩展,而如lw(load word)一类的则不扩展,因为一个word就是32位,可以满足寄存器的要求,如lb(load byte)则需要做符号位扩展
基本指令
op rd rs1 rs2 (rd: register destination; rs: register source)
比如一些基础的算术,逻辑运算,如:
add t0 t1 t2 # 将t1,t2寄存器的值相加,放置到t0寄存器中
sll t0 t0 t2 #将t0寄存器的值逻辑左移t2值位,放置到t0寄存器中
立即数指令(immediate instruction)
opi rd rs imm
比如addi t0 x0 2 t0的值被置位2,x0这个寄存器的值永远是0
立即数指令基本上都是在相应的操作码后面加个i(immediate)
分支指令(branch instruction)[有条件的跳转]
bop rs1 rs2 label
分支指令是rs1 bop rs2时,则会跳转到label的位置(条件跳转),当然后面的label也可以换做是数字,比如是个100,那就表示条件满足则令pc=pc+2*100
注意:pc是程序计数器,指示的是下一条指令的位置,修改pc即是指示程序下一条指令应该取哪的。我们的指令都是4字节的,合理来说应该*4才对,但好像是为了兼容16位的,所以*2
而作为一个标签,比如:
1 | |
这里我们当rs1==rs2会跳转到loop这个标签**,loop实际上指代的就是loop:...这条指令的地址**,实际在运行的时候它会被转换成一个偏移值,即分支指令的标签会被替换为:下一条指令地址相较于loop所指代指令地址的值,这个值是以字节为单位的,比如上面那里的值是0x38-0x20(0x1c + 0x4) = 0x18 = 24(10)字节,而按照上面说的会对数字*2处理,因此实际这个偏移量会是12(以2字节,也即是半字为偏移量的系数)
但实际上我在模拟器上试的时候显示的是6,即是以字为偏移量系数
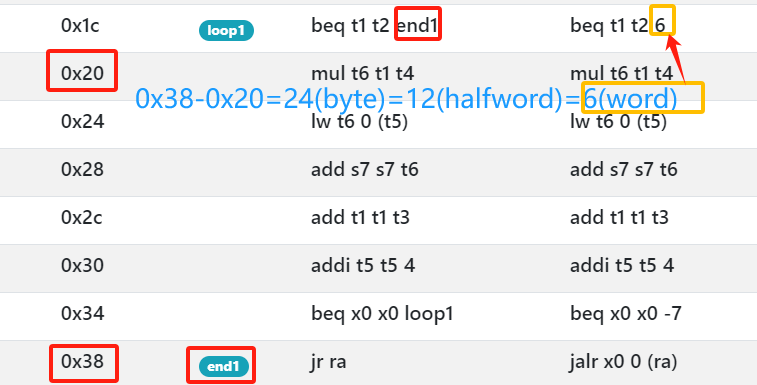
分支指令可以用来做for,while一类的循环
示例for(while差不多):
1 | |
注意:因为我们的分支指令是有条件的跳转,满足条件则跳到指定标签,即跳出循环;而对于循环而言是符合条件就在循环里面,因此写分支指令的时候,条件反着写更好,比如i<10则在循环内,那我们可以写作i≥10再跳到标签(跳出循环),然后需要注意循环条件的变化以及重新跳回循环的判断处(循环开始的标签)
数据传输指令[内存和寄存器的交流]
现在CISC和RISC指令集其实都很纷繁复杂,一种比较明显的区别是CISC中的访存操作存在隐式的,而RISC中则是显式的进行访存操作(通过访存取值如load,将值从寄存器写回内存的store)
lw rd imm(rs)rs里的值作为基址,imm作为偏移,从(rs+imm)表示的内存地址开始,依次取1个word的数据放到rd中去sw rd imm(rs)跟上面一样,不过是把rd里的32位的值,放置到以(rs+imm)表示的内存地址所指向的空间,一个地址指向的空间可以存放的是一个字节的数据,这里要放4个字节的数据,即(rs+imm)~(rs+imm+3)的空间内放的都是rd的值(具体放的顺序看大小端)lb rd imm(rs)跟lw差不多,不过这里取的是一个字节,要做符号位扩展,放到rd中去(如果是lbu这种,就是无符号扩展,前面填0补够位数就好了)sb rd imm(rs)跟sw差不多,不过因为是一个字节,直接塞到(rs+imm)指向的空间里面去就好
跳转指令[无条件的跳转]
jal rd label jump and link,一般这个rd是ra(return address)这个寄存器。在调用这条指令的时候会先把pc的值+4再存入ra,然后无条件跳转到label处,当然这个label可以是我们的函数名,也可以是100这样的东西,就相当于pc= pc + 2*100,将pc换成这个值,然后执行下一条指令的时候就会去取这个pc,就会跳到我们期望的位置了,label实际上也是这样,就是改变pc,让它跳到我们的函数区域。
伪指令
伪指令易于记忆和使用,会被汇编器翻译成一条或多条对应的汇编指令,本身并不具备扩展指令集的功能,类似于我们在C中喜欢用typedef / #define
mv rd rs,这个是让rd寄存器获取rs寄存器的值(register copy)li rd immli表示load immediate,往rd里放立即数的值la rd symbolla表示load address,对应auipc rd,symbol[31:12]和addi rd,rd,symbol[11:0]这两条指令,看起来就是把symbol的所有位数与PC相加然后放到了rd里面.之所以这样做,是因为我们的I型指令的立即数位数只有12位,U型指令的立即数位数有20位,通过这样操作,才可以让pc加上完整的symbol,然后放置到rd中去(这个symbol应该是偏移量,这样pc+symbol就是期望的地址)ret即pc从当前位置返回到ra所指向的指令位置,实际是通过jalr x0 ra 0即pc=ra+0,这是一条I型指令即jalr rd rs imm表示rd=pc+4,pc=rs+imm

伪操作
伪操作用于指导汇编器去理解汇编程序的行为.以.作为伪操作的开头
- 声明当前属于哪个段
.data已初始化的全局变量静态变量.text代码段.bss未初始化的全局变量静态变量
- 声明字串
str1: .string "哈哈哈哈哈2\n"
- 定义符号
.set tmp,100
- 定义字节/半字/字数组
byte_list: .byte 1,2,3word_list:.word 0x12345678,0x111
- 做地址对齐
.align 3.balign 4
标签和符号实际上都是代表内存地址(如str1:代表这里的(数据)地址和loop:代表这里的(指令)地址,本质上是一样的,只不过内存被分了段),然后易于记忆和使用,但是标签应该更多的是指用于流程控制(比如bne x0,x0,loop),而符号则是如变量这些(比如li t0,tmp,其中tmp在数据段被定义.set tmp,100)
二者之后都会被弄到符号表去
宏
宏实际上是由伪操作组成的
用.macro macro_name,para1,para2,...定义宏,用.endm结束宏,通过利用宏定义,我们可以弄出一些属于自己的频繁使用的伪指令,调用时直接宏名作为指令名,然后传入需要的参数即可
1 | |
汇编器处理宏时,会进行宏替换,把宏体里的形参用实参替换,生成的指令插入到对应的位置
函数调用
从jal这一条指令来看,函数调用即是我们在调用前把需要传入的参数放入a0~a7这些参数寄存器中,然后通过jal把下一条指令的地址放到ra中去,以便return,然后就跳转到jal中标定的label,即是我们的函数名,执行完毕后可以把要返回的值放入a0,然后ret。
实际中我们的函数调用涉及到栈帧概念.
栈帧
关于嵌套的函数
函数P调用函数Q,P称为调用者(caller),Q称为被调用者(callee),它们两个各自有需要保存的寄存器,只需要压栈保护自己要保存的东西即可,然后可以用另一方的寄存器。
指令格式
在RISC-V中,每一条指令都是4字节,这跟那种指令不定长的指令集不同,每条指令均为4个字节的设计,PC自动增4,以跳到下一跳指令的内存位置,同时也方便我们的硬件解析指令的设计,因为32位的指令中,哪个位置是放寄存器的,哪个位置是放操作码的是固定的。
以下是RV32I的指令集格式,共有六种类型的指令。其中opcode代表的是操作码,rd(register destination)代表的是目标寄存器,rs(register source)代表的是源操作器,funct3代表的是3位的用来指示该操作码具体指令的功能,funct7同理,imm代表的是立即数,有的imm是分为高低位被拆开的,imm有12位的,也有20位的,具体是针对不同的指令类型而言。
-
R-type代表的是三种寄存器的指令类型;
-
I-type代表的是load指令和有立即数的指令.而这里的立即数只取低12位,因此取值范围是[-2048,2047];
-
S-type代表的是store类型的指令;
-
SB-type代表的是分支指令;
-
U-type代表的是upper immediate,有LUI(load upper immediate)和AUIPC(add upper immediate PC)这两条指令,前者表示
lui rd imm # rd = imm << 12,后者为auipc rd imm # rd = pc + imm << 12.为什么需要这一个类型的指令呢?上面讲la伪指令讲了.因此如果想要将一个高于12位的立即数放入到寄存器中可以通过移位的指令达成,也可以通过LUI达成,如想要将0x00009000这个值放入寄存器中,通过lui t0 0x00009即可.如果想获得如0x12345abc,则lui t0 0x12345addi t0 t0 0xabc即可. -
UJ-type代表的是无条件跳转指令

- 有的版本会把SB类型写成B类型,把UJ写成J类型
- 立即数之所以被拆开来(比如S型指令),是因为整体的体系结构在设计的时候尽量让所有位置少变动,比如opcode一直在[0,6]位,保持尽可能相似的指令格式以降低硬件的设计复杂性
- SB型指令的立即数写作
imm[12|10:5]表示的是,指令格式的第31位存储的是立即数的第12位,指令格式的[25,30]位存储的是立即数的[5,10]位,之所以这么设计,我猜测跟硬件电路设计有关系 - 我们所有指令都是4字节的,需要做偶数对齐,即指令跳转的时候令PC+奇数肯定是错误的,因此PC+上的一定是偶数,因此SB型指令的第0位恒定是0(其实
PC+= imm*2,为啥乘2而不是4,感觉不是前面说的兼容16位,没找到有16位的RV16I这种东东,或许是从加上的是偶数这个地方出发,从而*2)
内存布局
我们整个程序都是存在内存中的,无论是指令还是数据(函数本质上也是指令和数据的复合体),因此将内存划分成了几个区域来存储我们的程序
有一部分数据是运行的时候不会变的,比如字符串,比如代码,这些就放在ROM区,而函数的调用涉及到的栈帧开销,对象创建涉及到的新内存开辟,统一成员信息的静态变量,全局可见的全局变量,则放在RAM区。
为此对于代码段给它起个名字叫text,对字符串这种只读的常量放置在rodata(这个在RISCV中还没有,用伪操作别用它,直接用data)处,它俩都是ROM区的;
对已初始化的全局变量,静态变量则放置在data处;对未初始化的全局变量静态变量则放在bss(block started by symbol segment)处;再往上就是heap,堆区,用于存放malloc等方式分配出来的变量;再往上就是stack区,用来存放函数。整体的内存布局如下图所示:


而在RISC-V内存分配图的右边则是一个栈帧的图,可以看到它的fp用作ebp的功能,sp用作esp的功能(这里的ebp和esp是x86系列里关于栈帧的俩指针)
关于代码编写
若想在以RISC-V架构的处理器上进行编程,需要一套对应的编程工具链(编译器,汇编器,链接器,加载器)
而目前大多数的处理器是x86架构或是ARM架构,因此需要先用QEMU模拟器,模拟对应的处理器,然后搭建对应的编译环境,相关信息请参阅参考文件中关于环境搭建的文章进行执行
本文考虑到学习成本,先不予搭建(其实有云服务器的话会好很多,不然太麻烦了)
后期有时间再搭建,玩一玩~
谷歌的colab有用于RISC-V的汇编学习的教程,在此编程~
主要是编程完后用clang和lld生成可执行文件,再提交可执行文件给RISC-V-ALE(RISC-V-assemble language environment)解析及运行
RISC-V的特权架构
RISC-V有三级特权架构,U-User S-Supervisor M-Machine,越往后的则权限等级越高
之所以会学到特权架构,是因为在使用colab的helloworld程序时,看到了一个叫做ecall的指令,这个指令很奇怪,就光秃秃一个操作符,没有操作数
ecall叫做environment call,是一个环境调用指令,调用它的时候,我们会从U模式切换到更高级的模式,在更高级的模式有一类称为CSR(control state register,控制状态寄存器)的寄存器,这是在S和M模式才有的寄存器,在进行模式切换的时候,会对我们的PC进行保存,保存在sepc/mepc,这个e实际上是exception,即是异常的意思,跟x86一样,RISC-V也存在中断和异常的处理。程序会在stvec/mtvec找到中断的基址,然后在scause/mcasue中找到这次异常对应的号码(见下图),然后发现是环境调用异常事件(发生地址跳转),就会去寄存器a7(参数寄存器那个a7)里看你想要处理的是什么系统调用(我们在a7存放的值被称为系统调用号,见再下一个图),然后a0~a6传入的是参数,处理好后会把返回值放到a0寄存器里面去。
![[m,s]cause code](https://s2.loli.net/2024/04/12/UD4uEVdS1fjKJbX.png)

详细了解中断可以从这篇文章去看RISC-V中断处理和中断控制器
关于X86中的Intel规范和AT&T规范

关于clang和lld
在colab提供的clang和lld中,大致说一下它二者的作用:
- clang
- lld 用作链接器
参考文件
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!