armV8架构及指令集知识
本文最后更新于:1 年前
Neon intrinsic入门
两个例子(学习自ARM的neon intrinsic教程)
其实还有个collision detection的例子,但感觉那个例子不如前两个例子好,因此没编程实现
- RGB deinterleaving
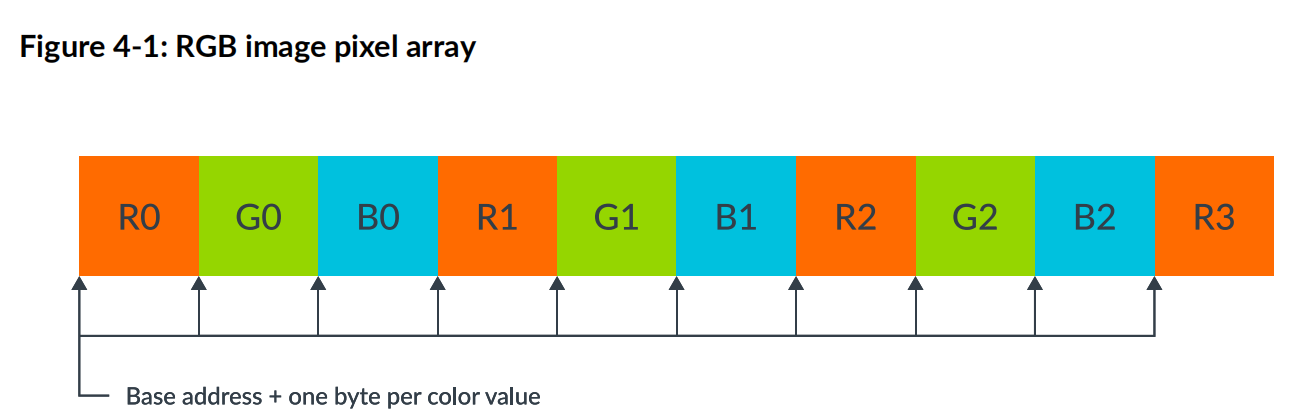
我们知道一个像素有三个颜色通道,R,G,B.每个像素点的颜色通道顺序排列,但如果我们想逐通道进行处理,则需要进行像素通道的分离,即从rgb这个数组中,分离三色通道,获得r,g,b三个单独的数组
用C实现如下:
1 | |
这样逐个元素取出然后放入数组是很容易联想到的一种方法,但是我们arm的通用寄存器是64位,每次处理都是64位的寄存器从内存load一个8位的数,又store回去.寄存器是宝贵的计算机资源,如此使用很浪费.
因此选择用neon实现,可以用向量寄存器来处理,128位则可以一次性处理16个8位的无符号整数(颜色范围[0,255]),但这样显然有问题,因为一次处理三个通道的数据,需要是3的倍数,因此可以选择用一个uint8x16x3_t的矩阵型数据类型来处理,这样一次采用三个向量寄存器处理即可.
用neon实现如下
1 | |
其中因为一次是处理了16个像素点(48个通道信息),所以像素长度要除以16(也可以让控制像素长度的步长每次走16步)
vld3q_u8是第一个接触到的neon intrinsic函数,v表示vector操作,ld表示这个函数的基本功能load,3q表示用到3个qword的寄存器,即是3个128位的向量寄存器,u8表示寄存器里的一个通道的数据是u8类型的,即unsigned int 8类型的.
它的返回值是一个uint8x16x3_t 的数据类型,将该类型的数据逐个取出,通过vst1q_u8的操作写到对应的数组中去
- matrix multiplication
以来考虑,其中是列主序的存储方式,C的维度是n*m,则普通的C矩阵乘如下:
1 | |
显然,这样的矩阵乘是最朴素的,那怎么优化呢?
不妨先从一个固定大小,然后维度比较小的矩阵来思考,我们的向量寄存器的宽度是128,那就是对于float32_t可以放4个,因此考虑一个4x4的小矩阵的乘法先,那么优化的过程如下图示:
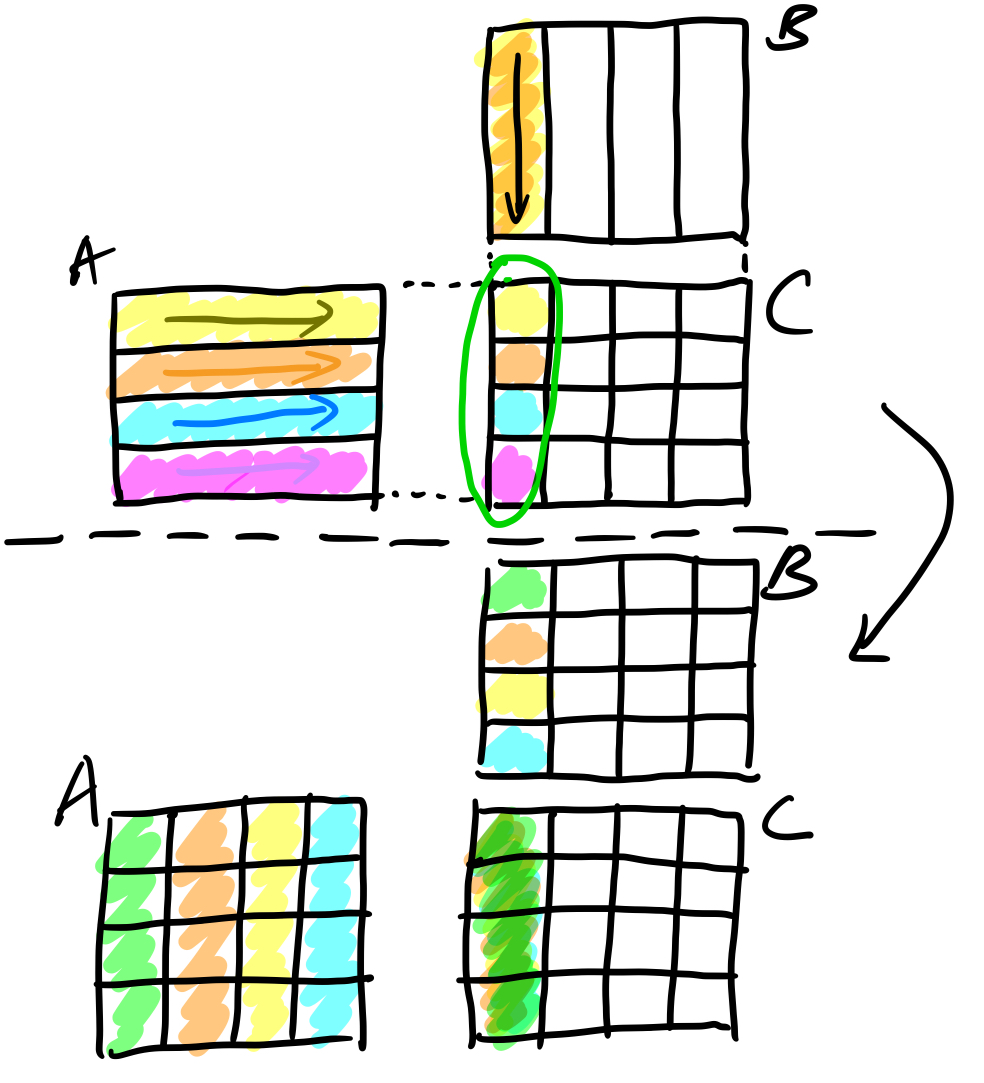
如图,我们想算C阵的一列数据,则按照A逐行与B的某一列做内积,则经过多次内积,可以得出C阵的一列数据;
但是这样对于A阵会频繁发生cache miss的问题,频繁访存导致latency,因此A阵最好也以列的方式取数据,通过分析我们知道,若要求C0(C阵的第一列),则A0通通要乘于B0[0](B阵第一列的第一个数据),A1要乘于B0[1],如此遍历完A阵(逐列)与B0列(逐元素)的数据,则可以计算出C0,大大减少了cache miss,且可以用neon intrinsic实现(减少指令数量,并有利于编译器做循环展开),代码如下:
1 | |
代码思路与上面画图的思路是一样的,由此便完成了一个4x4的neon intrinsic实现的矩阵乘
那么对于大的矩阵呢?如何处理?
其实可以划分为4x4的块,用我们上面优化后的矩阵乘进行计算,当然这样的情况针对的是行列两个维度均是4的倍数的,如果不是4的倍数,比如A的维度是514x515这样的,就可以做padding处理,这样也不用改动4x4的矩阵乘的代码
以下是一般阵的情况(这里没做padding):
1 | |
可以看出,n,m,k三个维度的步距都改作了4,注意C阵的值是需要累加完整个k维的循环,才可以得到C的一个小块(4x4)的结果,因此C的摆放位置有了变化,别的基本差不多.
函数规范
在说起函数规范前,先学一下用于neon的数据类型:
baseW_t: base表示基本的数据类型,然后W表示该类型的位宽,比如int8,uint8,float32这些,后面跟着的t是表示typedef的意思;baseWxL_t:这在上面的基础上加上了个L,实际上就是用了向量寄存器,L表示数据的个数,比如128位的寄存器,对于float32_t来说,就可以存4个,即float32x4_t(类似一维数组);baseWxLxN_t: 这个较上面的方法则类似二维数组,N表示baseWxL的个数,就比如分离RGB的例子,uint8x16x3_t表示的是有3个uint8x16的一维数组.
其实x86中比如avx2的数据类型也差不多,虽然看起来是__m256d,__m256i这样高深莫测的样子,但是内部的结构体也差不多
在ARM neon intrinsic入门的教程里,函数规范定义如下:
return_type v[p][q][r]opname[u][n][q][x][_high][_lane | _laneq][_n][_result]_type(args)
非常复杂,从左往右开始说
-
reture_type:返回类型,就是我们上面说到的neon的数据类型; -
v: 在所有intrinsic中必有,表示是一个vector操作
-
p: pair,成对操作
-
q: 饱和操作,就是数值溢出,不是对它做如取余(上溢),加上边界值(下溢)的操作,而是暂停在边界值
-
r: rounding向下取整
-
opname: 具体操作的名字,比如add,mul,sub之类的
-
u:
-
n: narrow,窄指令,输入操作数的向量是128位的,结果向量是64位的,类型相同,但是宽度减半,例子:
- ``
我在网上看到还有w(wide,宽指令),l(long,长指令)
- l: long,长指令,输入操作数的向量是64位的,结果向量是128位的,类型相同,但是宽度加倍,例子:
``
- w: wide,宽指令,输入操作数1个是64位的,1个是128位的,结果向量是128位的,类型相同,宽度上64位的是128位的一半,例子:
uint64x2_t vaddw_u32 (uint64x2_t a, uint32x2_t b) -
q: 表示用到是128的向量寄存器,quad word,默认是64位的double word
-
x:
-
_high:
-
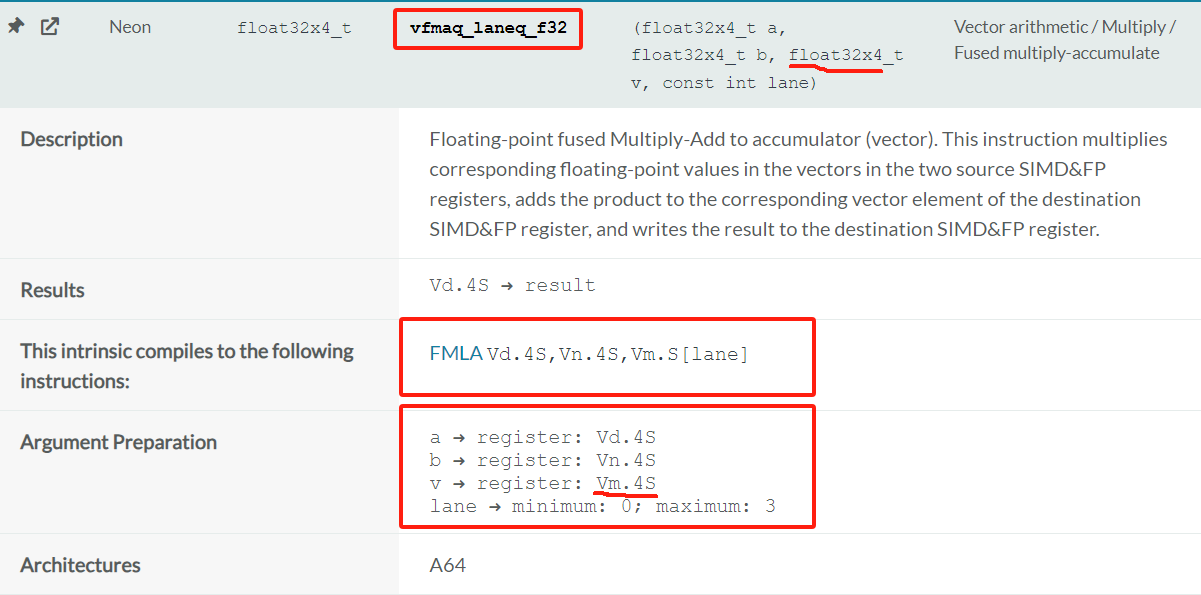
_lane | _laneq: 表示从一个向量的通道中取一个标量操作数.有q和无q的区别就是向量寄存器是用128位还是64位(感觉就默认的向量寄存器(不加q)就是用64位).下面是官网的两个例子:
-
-
_n: 表示有一个标量操作数,是要从参数中获取
-
_result:
-
_type: 表示每个通道的具体的数据类型
-
args: 输入参数

Neon相关的体系结构
下面的内容主要摘自ARM的Neon introducing:
Neon技术为指令集体系结构提供了一个专门的扩展,提供的额外指令能在多个数据流上并行的执行数学运算(SIMD)
为什么需要用到这个Neon呢?
处理大量数据集,主要的性能限制因素是执行数据处理指令所花费的大量CPU时间 -> 这个CPU时间取决于处理整个数据集的指令数量 -> 这个指令数量又取决于每条指令所能处理的数据项
When processing large sets of data, a major performance limiting factor is the amount of CPU time taken to perform data processing instructions. This CPU time depends on the number of instructions it takes to deal with the entire data set. And the number of instructions depends on how many items of data each instruction can process.
如果你现在处理的数值是小于最大位的大小,用SISD的话,额外的潜在的带宽是被浪费掉的
If the values you are dealing with are smaller than the maximum bit size, that extra potential bandwidth is wasted with SISD instructions.
即是我要对8位的数值去做一个ADD操作,那么每个8位的数值会被加载到一个单独的64位的寄存器.这样去处理数据,对硬件资源并没有很好的利用到.
SIMD指令是对多个数据项同时执行相同的操作.在一个较大的寄存器里,这些数据项会作为单独的通道被打包.(通道lane是完全隔离的,互相影响不到的)
Single Instruction Multiple Data (SIMD) instructions perform the same operation simultaneously for multiple data items. These data items are packed as separate lanes in a larger register.
Neon寄存器有128位的,也有64位的(就是把128位的高64位给置零,只用低64位,跟AVX兼容SSE差不多)
AArch64:Armv8-A架构的64位的执行状态.有时候一些GNU/Linux文档会把AArch64叫做ARM64.在AArch64状态下,处理器执行A64指令集(包含Neon指令)
AArch32:就是Armv8-A架构的32位执行状态,和Armv7几乎是一样的.在AArch32状态下处理器可以执行A32(在早期架构版本中是叫ARM)/T32(Thumb)指令集.这俩指令集向下兼容Armv7也有Neon指令
Armv8是64位的架构和用的是64位的寄存器,而我们的Neon用的是128位的寄存器,是因为Neon单元是在一个单独的128位寄存器的寄存器文件(硬件,可以参照RISC-V内有一个参考文件提及了处理器设计)上进行的操作
Neon寄存器包含了相同数据类型的元素的向量,这些相同数据类型的元素在输入输出寄存器中的位置是被称为通道lane(其实就跟数组一个样,不过更加具象化)
通道数n:就是指Neon指令会使得n个操作并行执行,这个n就是通道数,比如我们对一个float32x4_t,做加法操作,那这个4就是通道数,因为做了4个float32的加法操作(不过是一条指令).也就是说操作是针对通道lane的
显然,Neon向量的通道数就取决于向量大小(64位还是128位)和每个通道的数据类型(8位-B(byte) | 16位-H(halfword) | 32位-S(word,感觉single precision也可以) | 64位-D(doubleword))
以128位的向量来说有:
- 16个8位的元素(汇编中寄存器后缀会呈现为
.16B) - 8个16位元素(汇编中寄存器后缀会呈现为
.8H) - 4个32位元素(汇编中寄存器后缀会呈现为
.4S) - 2个64位元素(汇编中寄存器后缀会呈现为
.2D)
以64位向量来说有:
- 8个8位的(
.8B) - 4个16位的(
.4H) - 2个32位的(
.2S)
下图右侧的V0.4S是在汇编中向量寄存器作为操作码的写法(0表示V0,有32个向量寄存器)

在向量中元素是从LSB(最低有效位)开始放置的,就是element0(lane0的数据)会用到寄存器的LSB
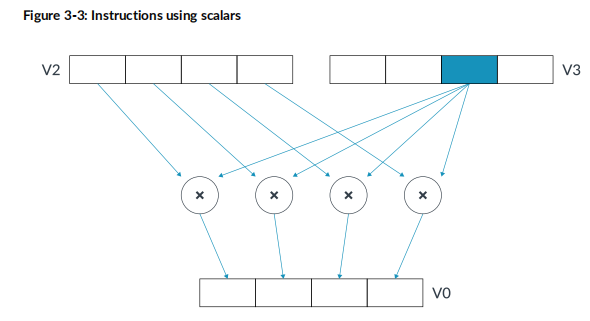
有些指令是向量跟一个向量里面的某一个位置的元素进行操作的,比如mul v0.4s v2.4s v3.s[2]就是V2寄存器里的4个float32_t和V3寄存器的lane2处的元素做乘法.如下图示:
一些ARM的基础知识
ARMv8有31个64位的通用寄存器,有32个128位的向量寄存器
Neon Assembly入门
神奇的指令
-
预取指令
prfm pldl1keep,[Rn,#imm],一般见到的是这样的格式
具体代码参考可见opDev中的数组加权和和box_filter盒子滤波的例子
参考文件
Neon intrinsic系列:
- intrinsic-set reference
- Learn the architecture - Optimizing C code with Neon intrinsics
- Learn the architecture - Introducing Neon
Neon Assembly系列:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!