本文最后更新于:2 个月前
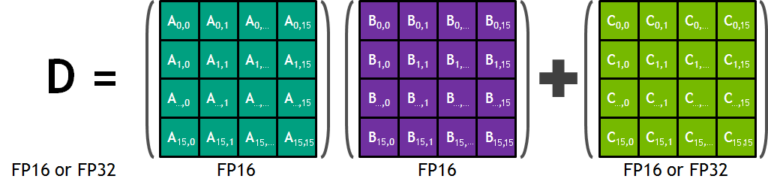
tensor core是一种专门处理矩阵乘运算的计算单元 ,可以加速矩阵乘运算,实现混合精度计算,见下图(不难看出这张图就是把数据按原样式搬移到指定地方,然后计算):
Volta架构的tensor core支持fp16和fp32下的混合精度矩阵乘法
可以通过c++的wmma(warp-level matrix multiply accumulate) api 调用tensor core,支持如D = A B + C D = AB+C D = A B + C C = A B + C C=AB+C C = A B + C
也可以通过wmma ptx 调用tensor core,相关指令如下: (此项废弃,因为wmma的ptx更像是Volta架构初次上新tensor core的尝试,不成熟,后面出的架构都用mma ptx )
wmma.load tensor core数据加载指令,将矩阵数据从gmem/smem 加载到寄存器wmma.storewmma.mma
还可以用mma ptx 指令调用tensor core:
ldmatrix tensor core数据加载指令,支持将矩阵数据从smem加载到寄存器 mma
注: 根据别人的逆向工程来看tensor core并没有独立的registerfile,也就是说用的还都是SM上的那个registerfile,跟cuda core用的是同样的寄存器
调用cuda core和tensor core的区别如下:
计算层级: cuda core是thread level; tensor core是warp level ;
计算维度: cuda core是一维逐点计算, tensor core是二维逐tile计算(这个可以用C阵的一个元素和一个tile理解)
计算依赖: wmma调tensor core要用fragment这个数据存储类,cuda core不用借助别的啥
实际上,在进行反汇编查看SASS码的时候可以发现,采用的是**LDSM(LoaD Matrix from Shared memory)和 HMMA**
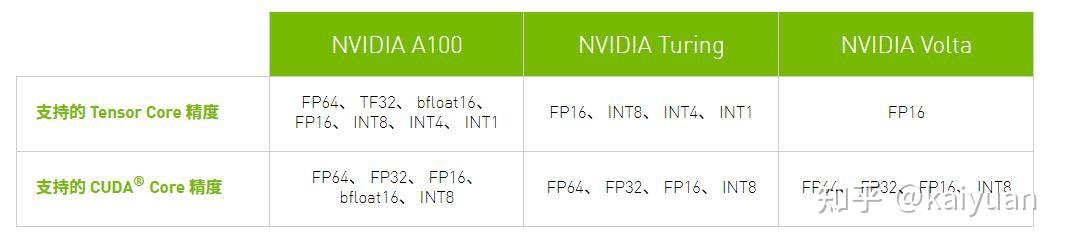
下表列出不同微架构下,不同代系的tensor core支持的混合精度运算类型以及单个MMA指令可以处理的矩阵乘大小:
C++调用WMMA的API
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 template <typename Use, int m, int n, int k, typename T, typename Layout=void >void load_matrix_sync (fragment<...> &a, const T* mptr, unsigned ldm) void load_matrix_sync (fragment<...> &a, const T* mptr, unsigned ldm, layout_t layout) void store_matrix_sync (T* mptr, const fragment<...> &a, unsigned ldm, layout_t layout) void fill_fragment (fragment<...> &a, const T& v) void mma_sync (fragment<...> &d, const fragment<...> &a, const fragment<...> &b, const fragment<...> &c, bool satf=false ) #include <mma.h> using namespace nvcuda;float > acc_frag;float > c_frag;
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 #include <cuda_runtime.h> #include <mma.h> #include <cstdio> #include <cstdlib> #include <cuda_fp16.h> using namespace nvcuda;#define WMMA_M 16 #define WMMA_N 16 #define WMMA_K 16 #define WARPSIZE 32 #define checkCudaError(func) { \ cudaError_t e = (func); \ if (e != cudaSuccess){ \ printf("CUDA ERROR %s %d : %s\n" ,__FILE__,__LINE__,cudaGetErrorString(e)); \ exit(-1); \ } \ } #define ceilOperation(a,b) ((a+b-1) / b) __global__ void sgemm_wmma_naive (const half* __restrict__ A, const half* __restrict__ B, half* __restrict__ C,int M,int N,int K) const int kCnt = ceilOperation (K,WMMA_K);const int bx = blockIdx.x;const int by = blockIdx.y;const int warpRow = by * WMMA_M;const int warpCol = bx * WMMA_N;if (warpRow > M || warpCol > N)return ;fill_fragment (cFrag,0.0 );for (int k=0 ;k<kCnt;k++){load_matrix_sync (aFrag,A+warpRow*K+k*WMMA_K,K);load_matrix_sync (bFrag,B+warpCol*K+k*WMMA_K,K);mma_sync (cFrag,aFrag,bFrag,cFrag);store_matrix_sync (C+warpRow*N+warpCol,cFrag,N,wmma::mem_row_major);int main (int argc,char ** argv) if (argc<4 ){fprintf (stderr,"Please input 4 elements,like: ./xx M N K\n" );exit (-1 );int gpu_id = 2 ;if (cudaGetDeviceProperties (&prop,gpu_id) == cudaSuccess){printf ("Using GPU:%d : %s\n" ,gpu_id,prop.name);cudaSetDevice (gpu_id);int M = atoi (argv[1 ]);int N = atoi (argv[2 ]);int K = atoi (argv[3 ]);size_t sizeA = sizeof size_t sizeB = sizeof size_t sizeC = sizeof malloc (sizeA);malloc (sizeB); malloc (sizeC);for (int i=0 ;i<M*K;i++){256.0f ; for (int i=0 ;i<K*N;i++){1.25f )/128.0f ; for (int i=0 ;i<256 ;i++)printf ("hA[%d]: %f; hB[%d]: %f\n" ,i,__half2float(hA[i]),i,__half2float(hB[i]));checkCudaError (cudaMalloc (&dA,sizeA));checkCudaError (cudaMalloc (&dB,sizeB));checkCudaError (cudaMalloc (&dC,sizeC));checkCudaError (cudaMemcpy (dA,hA,sizeA,cudaMemcpyHostToDevice));checkCudaError (cudaMemcpy (dB,hB,sizeB,cudaMemcpyHostToDevice));dim3 block (WARPSIZE) ;dim3 grid (ceilOperation(N,WMMA_N),ceilOperation(M,WMMA_M)) ;cudaDeviceSynchronize ();checkCudaError (cudaMemcpy (hC,dC,sizeC,cudaMemcpyDeviceToHost));for (int i=0 ;i<10 ;i++)printf ("hC[%d]:[%.6f]\n" ,i,__half2float(hC[i]));checkCudaError (cudaFree (dA));checkCudaError (cudaFree (dB));checkCudaError (cudaFree (dC));free (hA);free (hB);free (hC);cudaDeviceReset ();return 0 ;
注意:由于fp16是E5M10,即它的最大值和最小值是±65504,所以处理的时候需要注意一下控制范围,不然很容易INF
这里的代码等价于1个thread处理1个C阵的元素(即block(n,m)且只开1个block),此处采用的是1个warp处理C阵对应的1个tile(1个block只开1个warp,block的数目与N,M,WMMA_M,WMMA_N相关)
这是利用tensor core进行矩阵乘的最朴素代码
如果采用wmma api进一步做矩阵乘的优化,优化步骤其实也跟cuda core做gemm的优化步骤很像:
分块 .1个block计算某个固定的大小,block内的线程数目开在128,256这些数上(warp多好切换遮掩访存).分块还需要利用上各级存储结构,减少对全局内存的访问次数 ,即将数据移动到smem,移动到reg上,如果GPU架构允许,还可以使用上异步拷贝 ;
软流水 .实际上就是双缓冲(数据预取/存算重叠),使得计算不用等长时间的取数 ,计算访存相互遮掩;
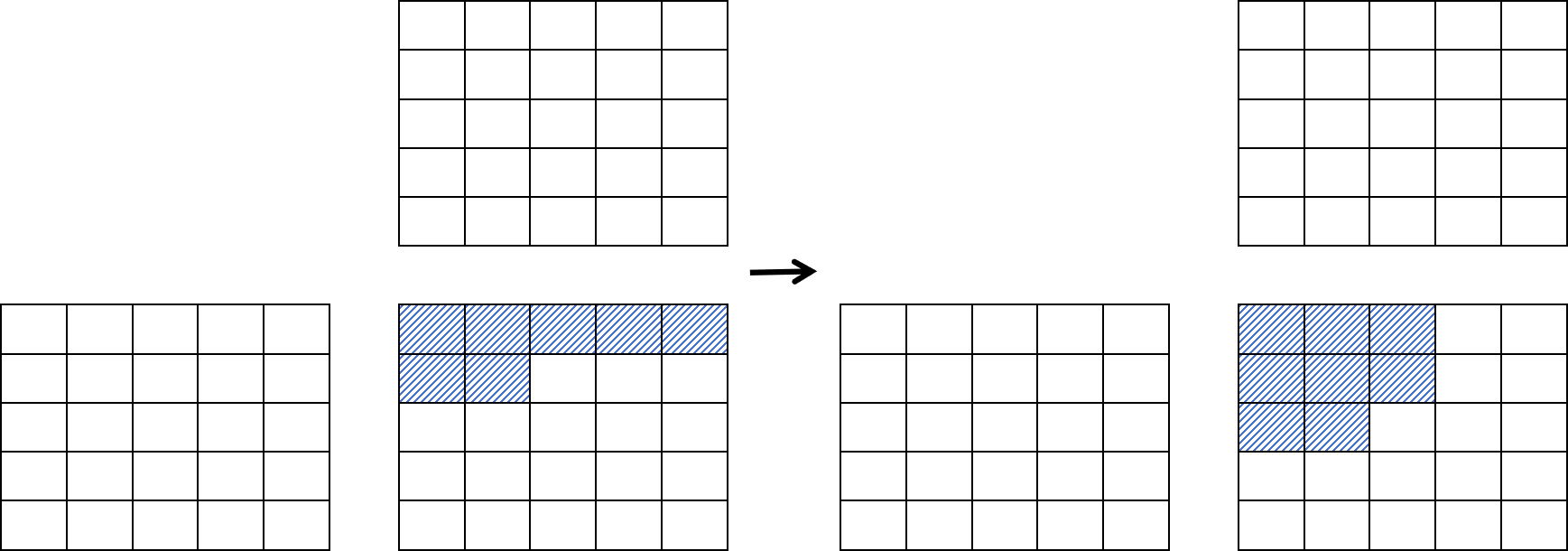
L2Cache的局部性 .当矩阵很大时,会启动非常多的block,这种情况下SM调度的顺序是沿着执行配置参数中的grid的Z->Y->X这三个维度的循环进行的 .以RTX3090为例,共82个SM,如果按照M,N,K = (16384,16384,16384)分块维度B M = 128 B_M=128 B M = 1 2 8 B N = 256 B_N=256 B N = 2 5 6 B K = 32 B_K=32 B K = 3 2 grid(64,128)来排block的话,会得到一个非常差劲的性能,如果填补上Z维,如grid(16,128,4)则会好很多.见下图,显然右侧的block调度的方式更优(图文可能没那么符合)
下面给出了利用wmma api做gemm的分块步骤,相较于之前的不同在于warp level以及warp内部需要分成多个fragment用于存储对应的数据
本部分优化的详细代码可参考:OperatorDev/wmma
那bank conflict呢?这里可以用padding来处理,更优的做法下面会讨论到👀
padding对于smem bank conflict的解决是对给定的smem的数组加"元素",一般这个加的元素数目与相关数据类型的向量化访问大小有关,不然你用上向量化访存,在读取某处时会发生misaligned address的错误;那padding这个东西其实影响大不大?个人感觉与smem所负责的分块大小有关,因为加的元素影响的是smem,如果smem负责的分块较大(怎么感觉在说废话,要移到smem上的肯定充分用满,那不移到smem上的算子,肯定数据移动量相对较小,移动到smem都是负优化),那么padding所浪费的smem其实是较大的一块,会影响到一个SM上并发的block数目,影响到occupancy,那么有些计算资源也没给用上.那这就很浪费了.
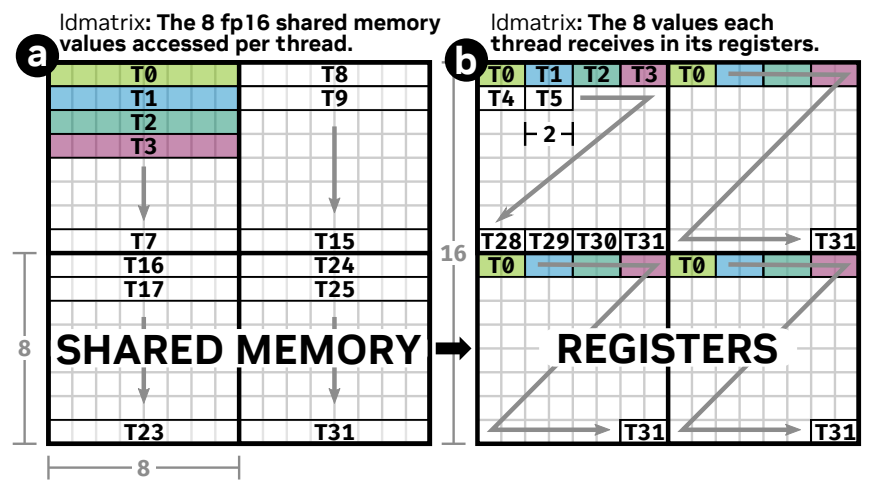
ldmatrix指令用于将数据从smem搬运到reg上,由于在搬运的时候我们为了减少访存指令数,一般都会采用向量化访存即float4,此时则以[T0,T7]为一个memory transaction,当然这里暂时不讨论bank conflict。而一个[T0,T7]中每个线程负责一个16B的数据,即搬运了一整个8x8的小矩阵。搬运得到的小矩阵是由warp内每个线程的R0寄存器保存矩阵的一部分,整个小矩阵由整个warp共同表达,这与朴素的LDS.128指令不同,不是一个线程各做各的,各自搬到各自私有的寄存器上。ldmatrix打破了这种私有的限制,由一整个warp协作式加载 这个8x8小矩阵
ldmatrix指令解释如下:
1 2 3 4 5 6 7 8 9 10 ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];
具体的数据搬移过程见下面两个图:
通过上图不难看出,我们如果想要获得一个16x16的矩阵,我们可以让T0-T31分别对应smem的某一个起始地址,然后通过它们一次性读入16B数据,即8个元素,然后再分配给同一warp其他线程的寄存器.寄存器是32位的,1个寄存器可以放下2个fp16的数据元素.即可得到右图所示的数据排放
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 #include <cstdio> #include <cstdint> #include <cuda_runtime.h> #include <cuda_fp16.h> #define SHAPE 8*8*4 #define checkCudaError(func) { \ cudaError_t e = (func); \ if (e!=cudaSuccess){ \ printf("CUDA ERROR %s %d : %s\n" ,__FILE__,__LINE__,cudaGetErrorString(e)); \ } \ } #define FLOAT4(pointer) (reinterpret_cast<float4*> (&(pointer))[0]) __global__ void test_ldmatrix (half* dIn,half* dOut) {int idx = threadIdx.x * 8 ; FLOAT4 (smemTmp[idx]) = FLOAT4 (dIn[idx]);uint32_t reg[4 ];__asm__ volatile ( "ldmatrix.sync.aligned.m8n8.x4.b16 {%0,%1,%2,%3},[%4]; \n" : "=r" (reg[0 ]), "=r" (reg[1 ]), "=r" (reg[2 ]), "=r" (reg[3 ]) : "l" (&smemTmp[idx]) ) reinterpret_cast <float *>(&dOut[idx])) = *(reinterpret_cast <float *>(®[0 ]));reinterpret_cast <float *>(&dOut[idx+2 ])) = *(reinterpret_cast <float *>(®[1 ]));reinterpret_cast <float *>(&dOut[idx+4 ])) = *(reinterpret_cast <float *>(®[2 ]));reinterpret_cast <float *>(&dOut[idx+6 ])) = *(reinterpret_cast <float *>(®[3 ]));int main () for (int i=0 ;i<SHAPE;i++){size_t sizeData = sizeof checkCudaError (cudaMalloc (&dLoad,sizeData));checkCudaError (cudaMalloc (&dStore,sizeData));checkCudaError (cudaMemcpy (dLoad,hLoad,sizeData,cudaMemcpyHostToDevice));1 ,32 >>>(dLoad,dStore);checkCudaError (cudaMemcpy (hStore,dStore,sizeData,cudaMemcpyDeviceToHost));for (int i=0 ;i<32 ;i++){printf ("T%02d " ,i);for (int j=0 ;j<8 ;j+=2 ){printf ("r%d %12f %12f " ,j/2 ,__half2float(hStore[i*8 +j]),__half2float(hStore[i*8 +j+1 ]));printf ("\n" );checkCudaError (cudaFree (dLoad));checkCudaError (cudaFree (dStore));return 0 ;
以上实验是对ldmatrix指令的整体认知,主要体现在整个warp协作式加载数据,使得整个矩阵由整个warp的每一个线程的部分寄存器来进行表示.其中加了.trans的个人建议理解先转置,后按照无.trans的情况处理,则可以与mma指令所需的matrixB的数据排布对应上
看完上面的ldmatrix指令,你会好奇,为啥要搞得这么复杂呢?
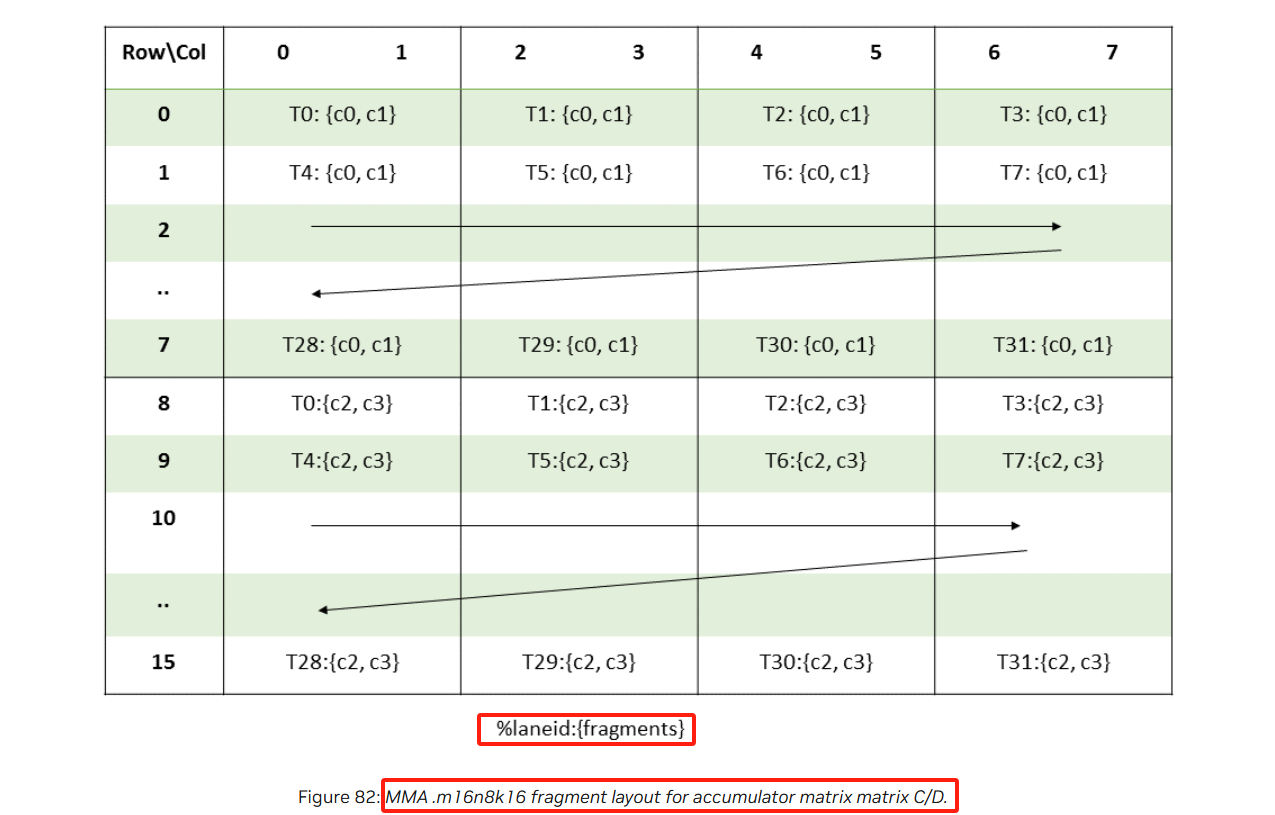
实际上ldmatrix是为了和mma指令搭配使用的,看下mma指令在M16N8K16情况下的1个warp涉及到的C tile和A tile以及B tile的数据在线程上的排布情况,你就知道为啥这么复杂了:
很明显,mma跟ldmatrix指令读取后数据分布到线程的情况是一样的,因此可以很好的搭配起来使用.那么如何结合起来使用呢?
需要注意到,ptx中mma的表示如下(这里贴的是半精度的):
1 2 3 4 5 6 7 8 mma.sync.aligned.m8n8k4.alayout.blayout.dtype.f16.f16.ctype d, a, b, c;
现在一般都是matrix_a是row-major,matrix_b是col-major,这也可以从上面的A,B,C阵的layout看出来.以16816为例我们知道对于matrix_a而言它需要先加载一个16x16大小的矩阵到寄存器上,这里以.x4的ldmatrix执行操作即可,其中T0-T15取列为0时的行首地址,T16-T31取列为8时的行首地址;对于matrix_b而言它在warp中的线程上的数据排布稍显奇怪,T0-T3中的寄存器RB0们的元素呈现col-major,回看上面ldmatrix的实验可知,就是将matrix_b s2r的时候加了个.trans限定符即可,其中T0-T15取列为0时的行首地址(.x2就行)
以下是一个mma的例子,代码看test_mma :
上面这个例子中的MNK取了16816,恰好使用一条mma指令即可完成,源码细节在链接中查看
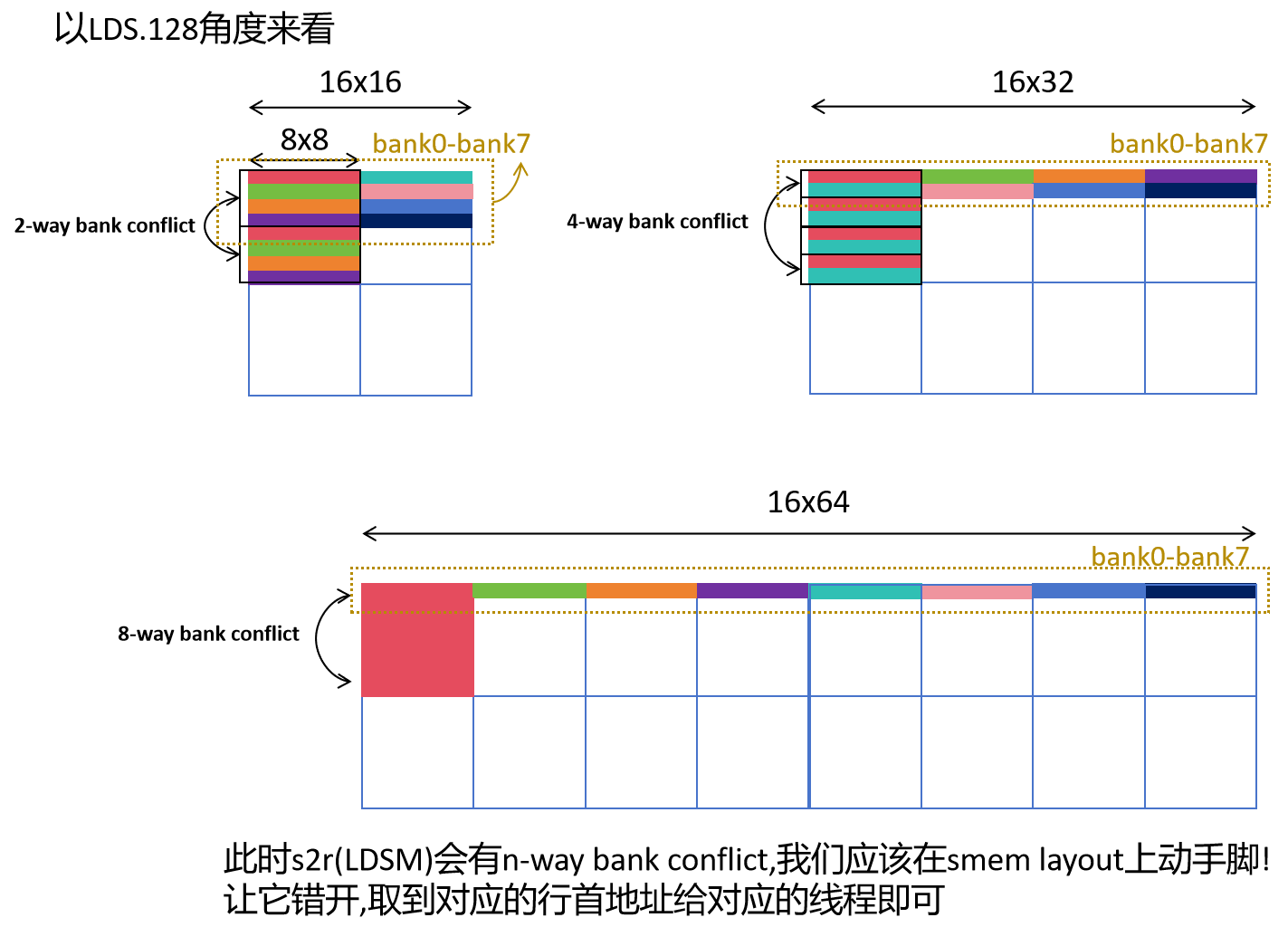
回答上面的问题,那我们这样取数据(LDSM,就是ldmatrix)会有bank conflict嘛?
以下图16x16,16x32,16x64的这么些个阵,给它从gmem放到smem上,然后分别由1,2,4个warp处理,它们分别会发生不同的n-way bank conflict(图中是以LDS.128来描述此时的bank排布).显然我们不能将数据从gmem朴素的移到smem上而不做任何位置上的调动,这样会导致大量的smem bank conflict.
本质上,我们只需要对同一行的新元素们 (以fp16来说这个新元素就是由8个连续的fp16元素组成的一个块)做shuffle就可以实现bank conflict free ,注意,这只是改变行内的新元素排列的顺序 .而这个行内的界定又取决于连续访问新元素的能力,即此时的新bank数目 为所谓的一行 .
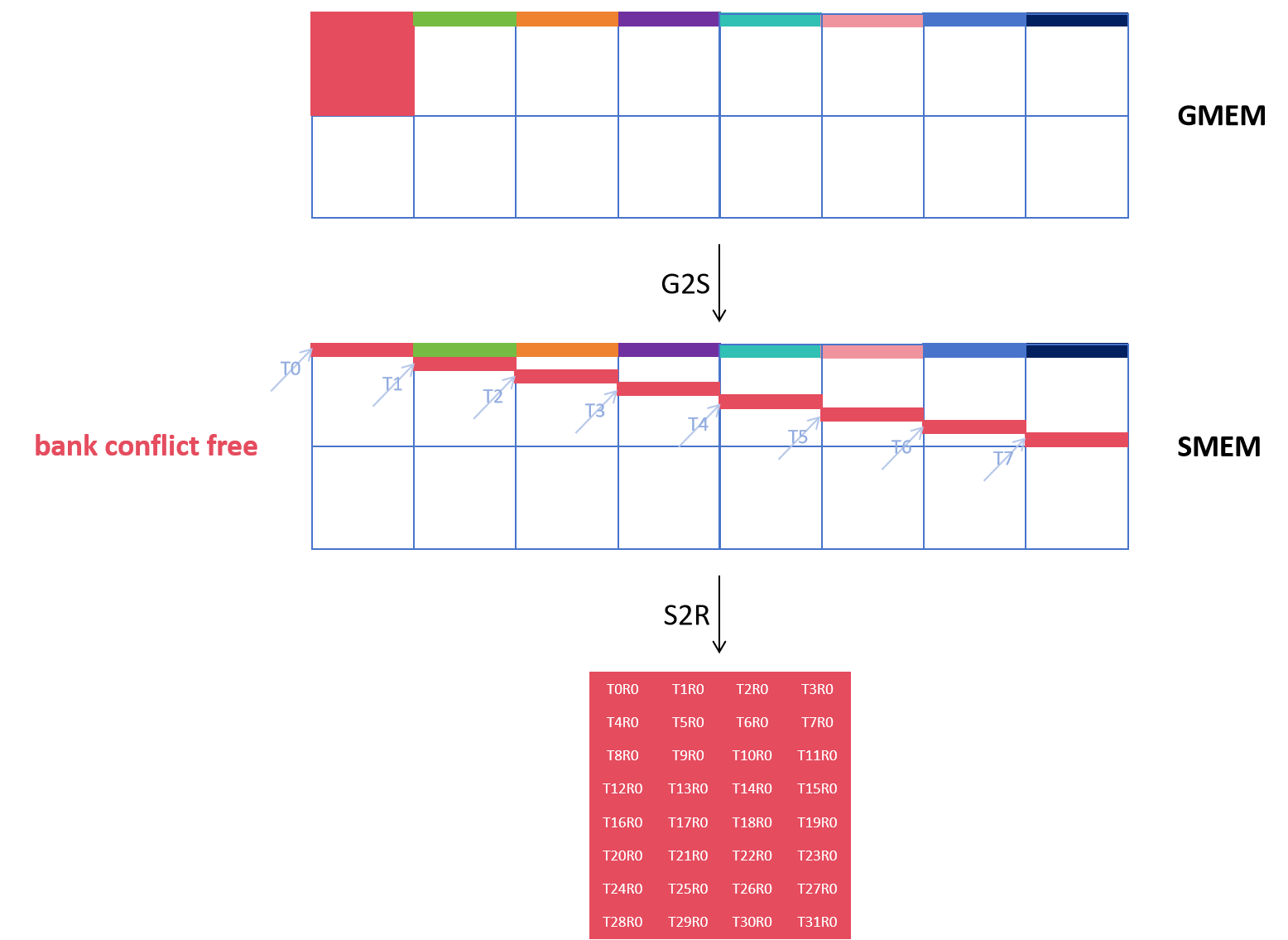
以cutlass来说,所用的手段就是icol = irow ^ icol,我们的每个线程将数据从gmem搬到smem时,每个线程是负责搬运一定的大小,有对应的行列,进行一定的操作(含异或),便可以实现类似下图的搬运(g2s);然后为了利用上LDSM,根据warpId,laneId以及ldmatrix的取数顺序,即laneId % 16做行, laneId / 16散开成列的0,1,这里的0,1是以新元素的大小来描述的,实际要乘上个8,还有根据warpId对不同warp搬运的位置进行定位,即可实现smem bank conflict free的LDSM
以上实验代码详见:OperatorDev/test_swizzle.cu ,实验效果分析如下:
朴素情况下,对16x64的4warp调用ldsm,会发生7(单个memory transaction的访问冲突数目)*4(1个warp的memory transaction数)*4(warp数目)*1(block数目)=112次访问冲突
经过手动swizzle后,变为了0次:
ncu中的两个指标
wavefront类似于cycle的表述,它代表了处理请求所需的时钟周期数,比如你无smem bank conflict,则我就是1个cycle完成访问,否则因为并行转为串行,n-way bank conflict就会使得你需要n个cycle,而这n个cycle乘上1个warp里的memory transaction数目,再乘上warp数,再乘上block数即是ncu给出的值 bank conflict之于ncu,比如说4-way bank conflict,那就是一个memory transaction有3次冲突,单个memory transaction的冲突数乘上一个warp内有的memory transaction数目,再乘上warp数和block数,即是ncu输出的smem bank conflict数目
这个知识点目前存在的一个问题,如何封装成函数模板?想按照cutlass那样封,但自己没想到咋计算对应的关系,只会对给出的用例计算how to achieve bank conflict free,无法更高的抽象化,后续继续学习
参考文件: